在了解了基本的 RNN 架构之后,我们来看如何将其应用于三类自然语言处理任务:序列分类(sequence classification)任务,如情感分析和主题分类;序列标注(sequence labeling)任务,如词性标注;文本生成(text generation)任务,包括一种称为编码器-解码器(encoder-decoder)的架构。
13.3.1 序列标注
在序列标注任务中,网络的目标是为输入序列中的每个元素分配一个标签,该标签来自一个小型且固定的标签集合。 一个经典的序列标注任务是词性标注(part-of-speech tagging, POS),即为句子中的每个词赋予语法标签,如 NOUN(名词)或 VERB(动词)。 我们将在第 17 章详细讨论词性标注,但这里先给出一个示例说明。 在基于 RNN 的序列标注方法中,输入是词嵌入,输出则是通过 softmax 层在给定标签集上生成的标签概率分布,如图 13.7 所示。
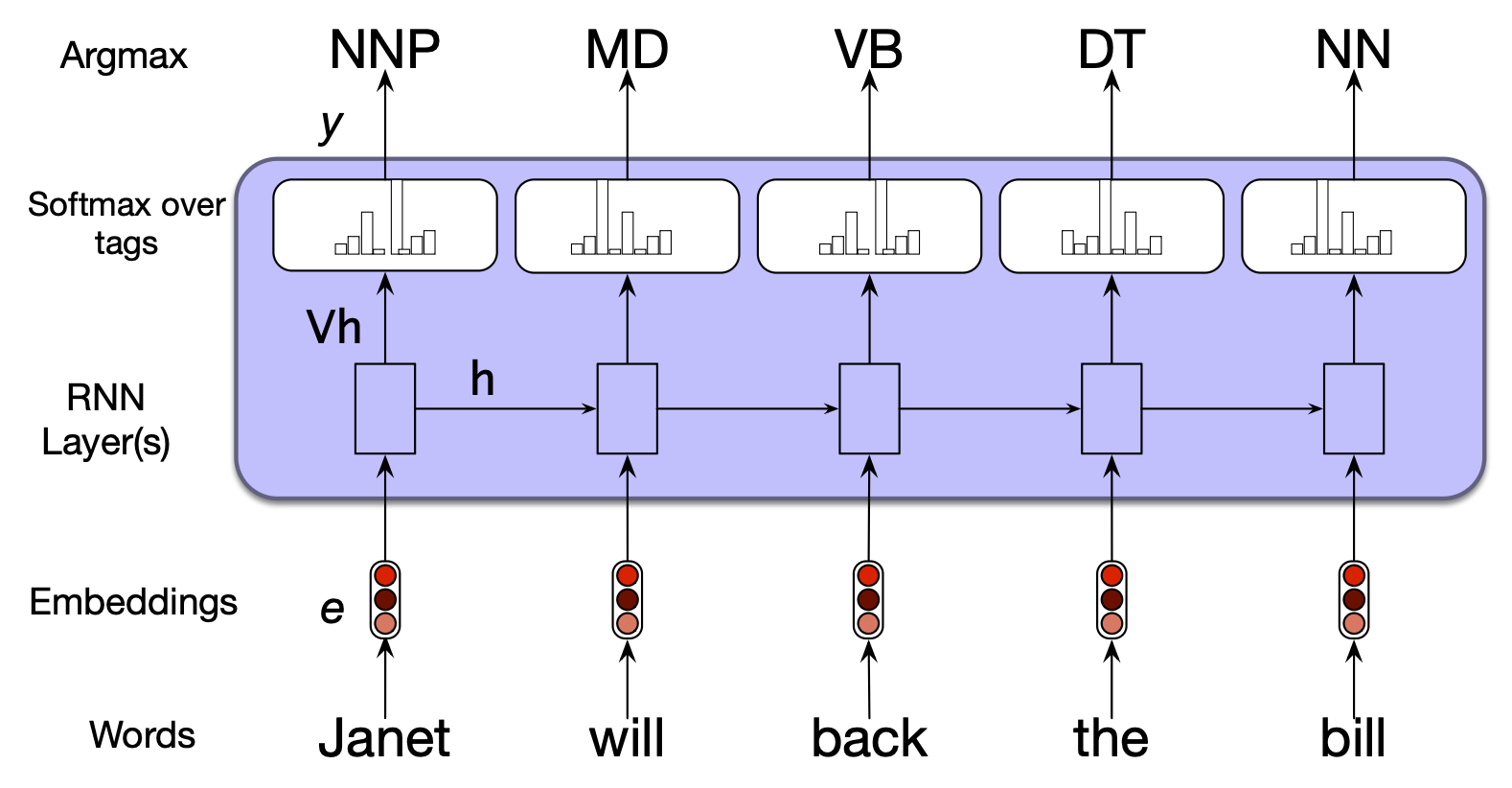
图 13.7 使用简单 RNN 进行词性标注的序列标注任务。 词性标注的目标是为句子中的每个词分配一个语法标签,这些标签来自一个预定义的标签集。 (本句中的标签包括 NNP(专有名词)、MD(情态动词)等;我们将在第 17 章完整描述词性标注任务。) 预训练词嵌入作为输入,每个时间步通过 softmax 层输出词性标签的概率分布。
在该图中,每个时间步的输入是与输入词元对应的预训练词嵌入。 RNN 模块是一个抽象表示,代表一个按时间展开的简单循环网络:每个时间步包含输入层、隐藏层和输出层,并共享权重矩阵 $\mathbf{U}$、$\mathbf{V}$ 和 $\mathbf{W}$。 网络在每个时间步的输出是由 softmax 层生成的词性标签集上的概率分布。
要为给定输入生成标签序列,我们对输入序列执行前向推理,并在每个时间步选择 softmax 输出中概率最高的标签。 由于我们在每个时间步都使用 softmax 层来生成输出标签集上的概率分布,因此训练时依然采用交叉熵损失函数。
13.3.2 RNN 用于序列分类
RNN 的另一种用途是对整个序列进行分类,而不是对序列中的各个词元分别打标签。 这类任务通常称为文本分类(text classification),例如情感分析或垃圾邮件检测——这些任务将一段文本分为两类或三类(如正面或负面);也包括具有大量类别的情况,例如文档级主题分类,或客服场景中的消息路由。
在此类任务中应用 RNN 的方法如下:我们将待分类的文本逐词输入 RNN,每个时间步生成一个新的隐藏层表示。 然后,我们可以取文本最后一个词对应的隐藏状态 $\mathbf{h}_n$,作为整个序列的压缩表示。 接着,将该表示 $\mathbf{h}_n$ 输入一个前馈网络,由该网络通过 softmax 在所有可能类别上选择最终类别。 图 13.8 展示了这一方法。
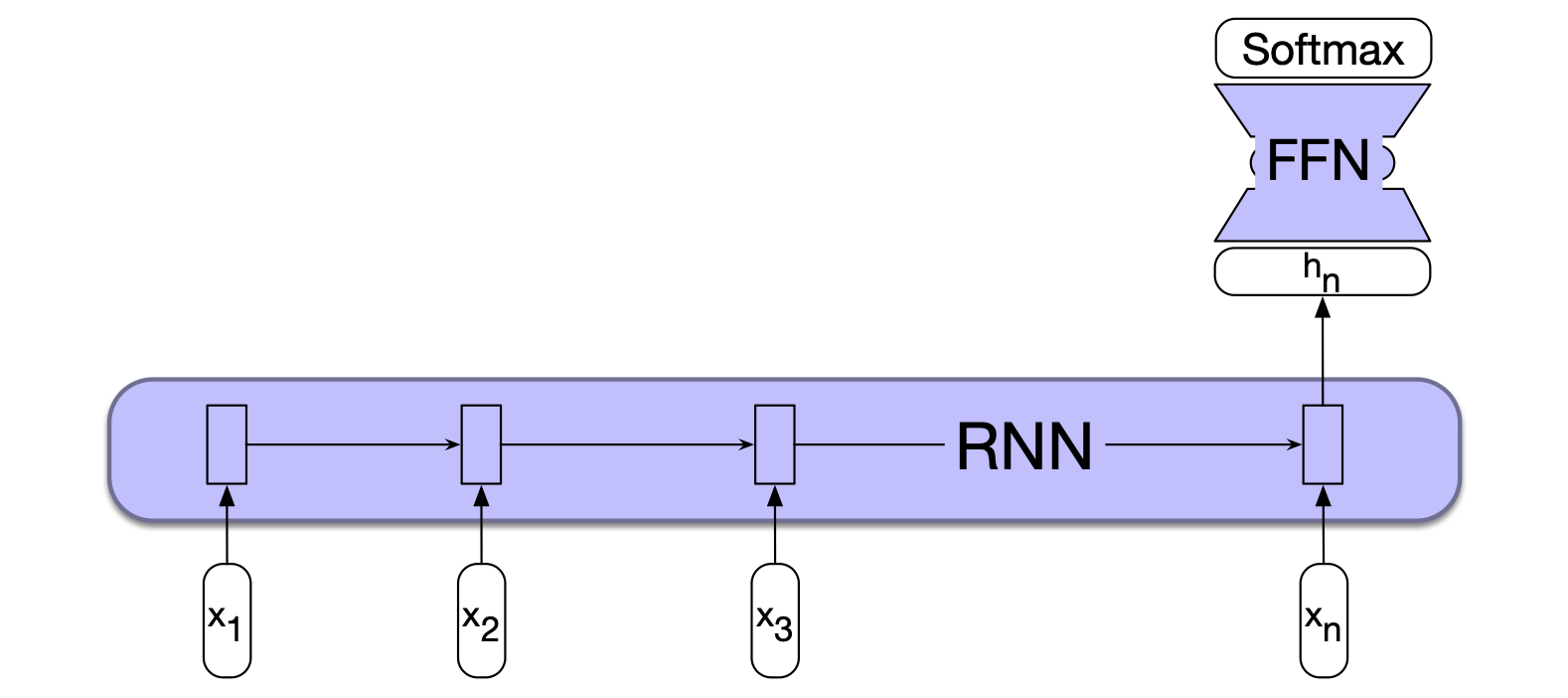
图 13.8 使用简单 RNN 结合前馈网络进行序列分类。 RNN 的最终隐藏状态被用作前馈网络的输入,由该前馈网络完成分类任务。
注意,在这种方法中,我们不需要序列中除最后一个词以外其他位置的中间输出。 因此,这些中间位置不产生任何损失项。 网络权重的训练完全基于最终的文本分类任务所定义的损失函数。 具体而言,前馈分类器的 softmax 输出与交叉熵损失共同驱动训练过程。 分类任务产生的误差信号会从分类器开始反向传播:先经过前馈分类器的所有权重,再传回其输入,然后继续反向传播至 RNN 中的三组权重($\mathbf{U}$、$\mathbf{V}$、$\mathbf{W}$),如第 13.1.2 节所述。 这种利用下游任务的损失信号调整整个网络权重的训练方式,被称为端到端训练(end-to-end training)。
除了仅使用最后一个词的隐藏状态 $\mathbf{h}_n$ 来表示整个序列外,另一种常见做法是对序列中所有词 $i$ 的隐藏状态 $\mathbf{h}_i$ 应用某种池化(pooling)函数。 例如,我们可以对全部 $n$ 个隐藏状态进行元素级平均,得到一个序列表示:
$$ \mathbf{h}_{\text{mean}} = \frac{1}{n} \sum_{i=1}^{n} \mathbf{h}_i \tag{13.15} $$或者,我们可以取元素级最大值(element-wise max): 对于一组 $n$ 个向量,其元素级最大值是一个新向量,其中第 $k$ 个元素是这 $n$ 个向量第 $k$ 个元素中的最大值。
然而,RNN 能处理长上下文的能力也带来了挑战: 在很长的序列上,很难将误差信号成功地反向传播回整个输入序列的起点。 我们将在第 13.5 节详细讨论这一问题及其常用解决方案。
13.3.3 基于 RNN 语言模型的文本生成
基于 RNN 的语言模型也可用于生成文本。 文本生成,连同图像生成和代码生成,构成了人工智能的一个新兴领域,通常被称为生成式 AI(generative AI)。 如果你已经读过第 7 章和第 8 章,可能对此已有了解;但为了照顾不同阅读顺序的读者,我们在此重新介绍这一内容。
回顾第 3 章,我们曾介绍过如何利用 n-gram 语言模型生成文本,其方法借鉴了克劳德·香农(Claude Shannon, 1951)以及心理学家乔治·米勒(George Miller)和詹妮弗·塞尔弗里奇(Jennifer Selfridge, 1950)几乎同时提出的采样(sampling)技术。 首先,根据某个词作为序列起始的合适程度,随机采样一个起始词。 然后,在此前已选词的基础上继续条件采样下一个词,直到达到预设长度或生成结束符为止。
如今,这种利用语言模型、通过不断以先前生成的词为条件来采样下一个词的增量式生成方法,被称为自回归生成(autoregressive generation)或因果语言模型生成(causal LM generation)。 该过程本质上与第 48 页描述的方法相同,只是被适配到了神经网络的上下文中:
- 首先,将句子起始标记
<s>作为初始输入,通过模型得到 softmax 概率分布,并从中采样第一个输出词; - 接着,将该词的词嵌入作为下一时间步的输入送入网络,并以同样方式采样下一个词;
- 重复此过程,直到采样到句子结束标记
</s>,或达到预设的最大生成长度。
从技术上讲,自回归(autoregressive)模型是指在时刻 $t$ 预测一个值,该预测基于对之前时刻(如 $t-1, t-2, \dots$)值的线性函数。 尽管语言模型并非线性的(因其包含多层非线性变换),我们仍宽泛地将这种生成方式称为自回归生成,因为在每个时间步生成的词都依赖于模型在前一步所选择的词。 图 13.9 展示了这一生成过程。 图中,RNN 的隐藏层细节和循环连接被封装在蓝色模块内。
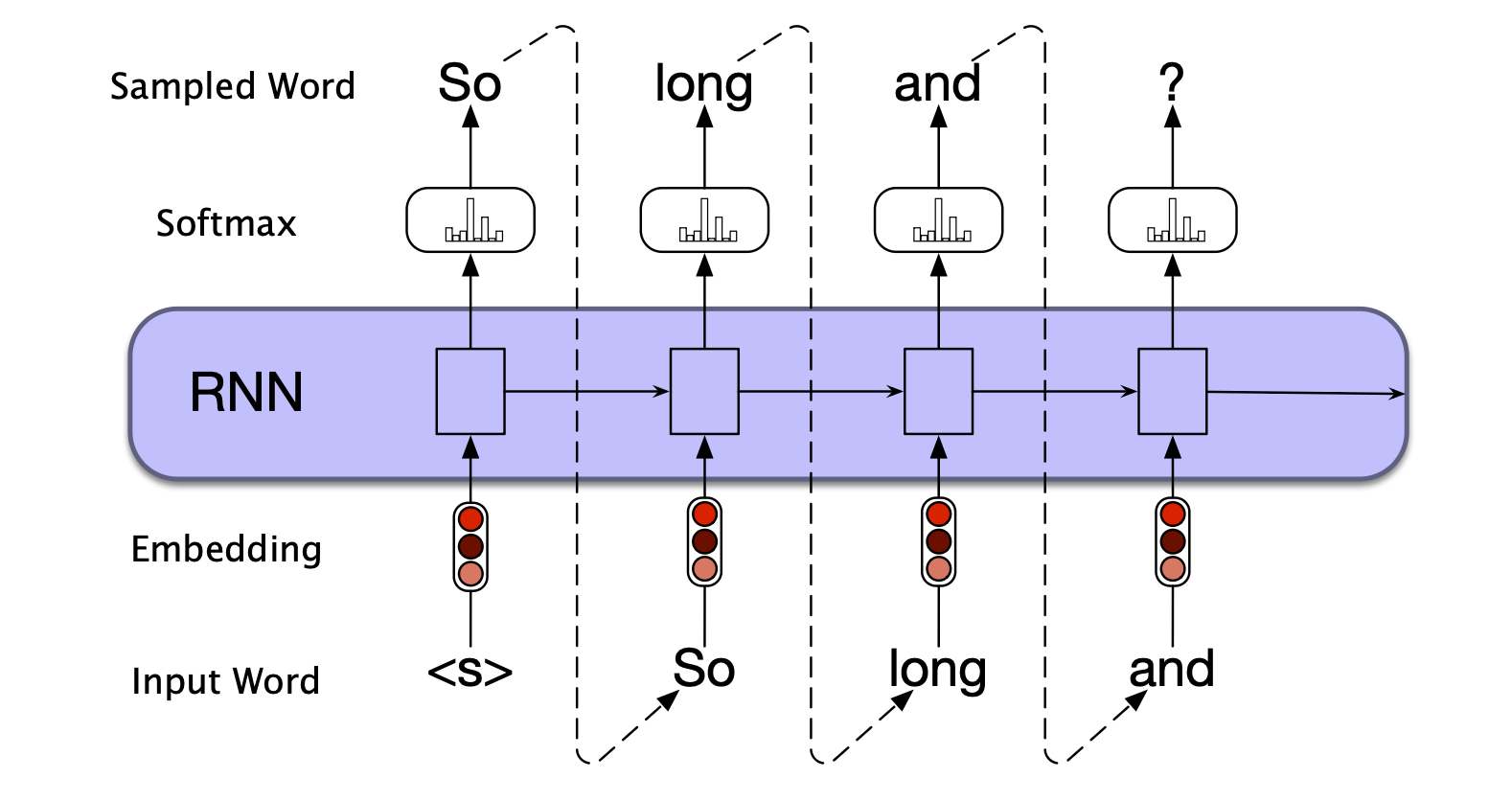
图 13.9 使用基于 RNN 的神经语言模型进行自回归生成。
这种简单架构构成了当前机器翻译、文本摘要和问答等任务中最先进方法的基础。
这些方法的关键在于:为生成组件提供一个合适的上下文作为“引导”(prime)。
也就是说,我们并不只是用 <s> 来启动生成,而是可以提供更丰富的、与具体任务相匹配的上下文:在翻译任务中,上下文是源语言句子;在摘要任务中,上下文是我们希望总结的长文本。