现在我们来看如何将 RNN 应用于语言建模任务。 回顾第 3 章的内容,语言模型的目标是:给定前面的上下文,预测序列中的下一个词。 例如,如果前面的上下文是 “Thanks for all the”,我们想知道下一个词是 “fish” 的可能性有多大,就需要计算:
$$ P(\text{fish} \mid \text{Thanks for all the}) $$语言模型能够为词汇表中每一个可能的下一个词分配这样一个条件概率,从而得到一个完整的概率分布。 我们还可以利用链式法则,将这些条件概率组合起来,为整个词序列分配概率:
$$ P(w_{1:n}) = \prod_{i=1}^{n} P(w_i \mid w_{< i}) $$第 3 章介绍的 n-gram 语言模型通过统计目标词与前 $n-1$ 个词共同出现的频次来计算概率。 因此,其上下文长度固定为 $n-1$。 而第 6 章中的前馈神经语言模型则使用一个固定大小的滑动窗口作为上下文。
RNN 语言模型(Mikolov 等,2010)逐词处理输入序列,试图根据当前词和前一时刻的隐藏状态来预测下一个词。 因此,RNN 既没有 n-gram 模型的有限上下文问题,也没有前馈语言模型的固定上下文限制。因为原则上,隐藏状态可以编码从序列开头一直到当前时刻的所有历史信息。 图 13.5 示意了前馈神经网络(FFN)语言模型与 RNN 语言模型之间的这一关键区别: RNN 语言模型使用前一时刻的隐藏状态 $\mathbf{h}_{t-1}$ 作为过去上下文的表示。
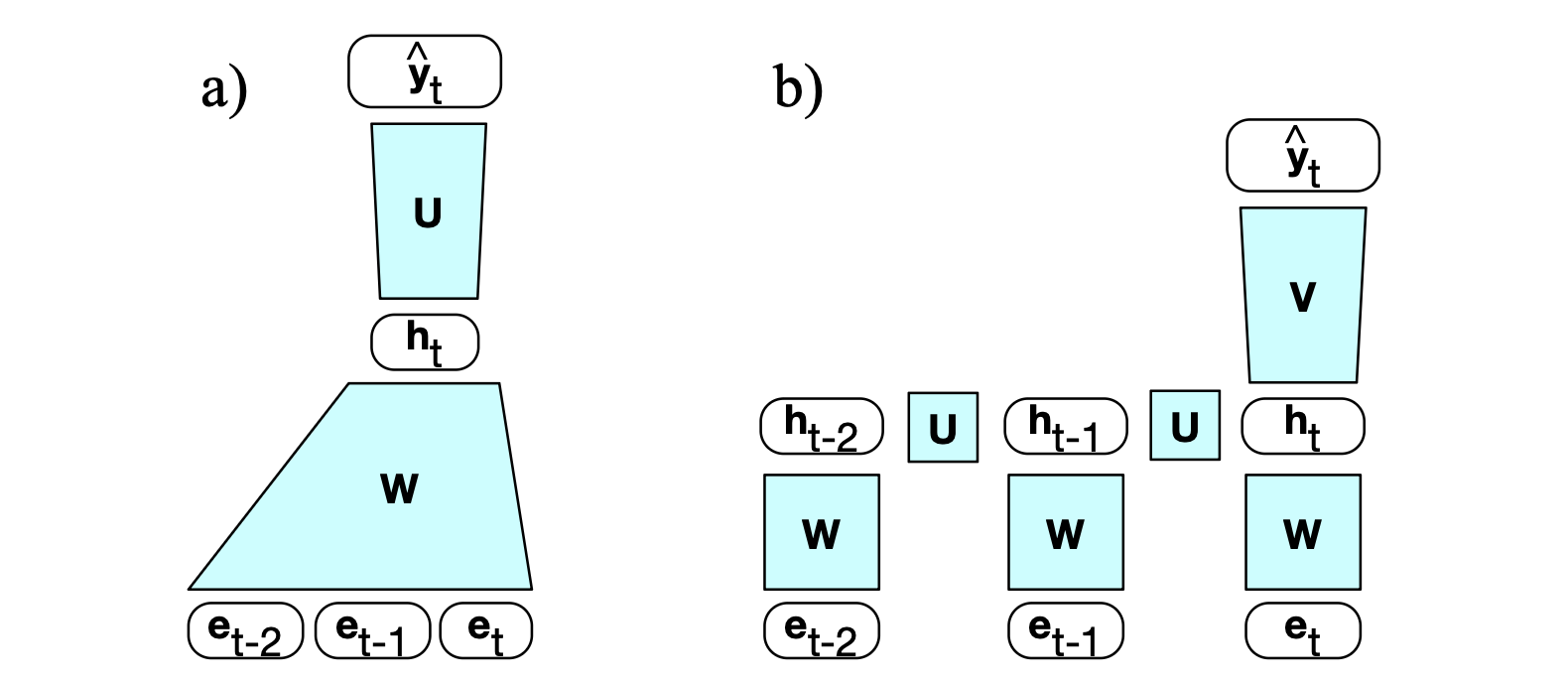
图 13.5 两种语言模型架构在文本上移动的简化示意图,展示了长度为三个词元的示意上下文: (a) 前馈神经语言模型,上下文是固定长度的,作为输入提供给权重矩阵 $\mathbf{W}$; (b) RNN 语言模型,其中隐藏状态 $\mathbf{h}_{t-1}$ 对先前上下文进行了总结。
13.2.1 RNN 语言模型中的前向推理
RNN 语言模型中的前向推理过程与第 13.1.1 节所述完全一致。 输入序列 $\mathbf{X} = [\mathbf{x}_1, \dots, \mathbf{x}_t, \dots, \mathbf{x}_N]$ 由一系列词组成,每个词表示为一个大小为 $|V| \times 1$ 的 one-hot 向量。输出预测 $\hat{\mathbf{y}}$ 是一个向量,表示整个词汇表上的概率分布。 在每一步,模型首先使用词嵌入矩阵 $\mathbf{E}$ 获取当前词的嵌入表示; 然后将该嵌入与权重矩阵 $\mathbf{W}$ 相乘;再将其与前一时刻的隐藏层(经权重矩阵 $\mathbf{U}$ 加权)相加,从而计算出新的隐藏层。 接着,该隐藏层用于生成输出层,并通过 softmax 层转换为整个词汇表上的概率分布。 具体而言,在时刻 $t$ 的计算如下:
$$ \begin{align*} \mathbf{e}_t &= \mathbf{E} \mathbf{x}_t \tag{13.4} \\ \mathbf{h}_t &= g(\mathbf{U} \mathbf{h}_{t-1} + \mathbf{W} \mathbf{e}_t) \tag{13.5} \\ \hat{\mathbf{y}}_t &= \text{softmax}(\mathbf{V} \mathbf{h}_t) \tag{13.6} \end{align*} $$在使用 RNN 进行语言建模时(我们在第 9 章讨论 Transformer 时会再次看到这一点),通常假设嵌入维度 $d_e$ 与隐藏层维度 $d_h$ 相同。 因此,我们将两者统称为模型维度 $d$。 于是嵌入矩阵 $\mathbf{E}$ 的形状为 $[d \times |V|]$;输入 $\mathbf{x}_t$ 是一个形状为 $[|V| \times 1]$ 的 one-hot 向量。 乘积 $\mathbf{e}_t = \mathbf{E} \mathbf{x}_t$ 的形状为 $[d \times 1]$。 权重矩阵 $\mathbf{W}$ 和 $\mathbf{U}$ 的形状均为 $[d \times d]$,因此 $\mathbf{h}_t$ 的形状也是 $[d \times 1]$。 输出权重矩阵 $\mathbf{V}$ 的形状为 $[|V| \times d]$,所以 $\mathbf{Vh}_t$ 的结果是一个形状为 $[|V| \times 1]$ 的向量。 该向量可视为在给定隐藏状态 $\mathbf{h}$ 所提供的证据下,对词汇表中每个词的打分。 将这些得分通过 softmax 函数进行归一化,即可得到一个合法的概率分布。 词汇表中某个特定词 $k$ 作为下一个词的概率,由 $\hat{\mathbf{y}}_t[k]$ 表示,即 $\hat{\mathbf{y}}_t$ 的第 $k$ 个分量:
$$ P(w_{t+1} = k \mid w_1, \dots, w_t) = \hat{\mathbf{y}}_t[k] \tag{13.7} $$整个序列的概率等于序列中每个词概率的乘积。这里我们用 $\hat{\mathbf{y}}_i[w_i]$ 表示在时刻 $i$ 真实词 $w_i$ 的概率:
$$ \begin{align*} P(w_{1:n}) &= \prod_{i=1}^{n} P(w_i \mid w_{1:i-1}) \tag{13.8} \\ &= \prod_{i=1}^{n} \hat{\mathbf{y}}_i[w_i] \tag{13.9} \end{align*} $$13.2.2 RNN 语言模型的训练
要将 RNN 训练为语言模型,我们采用与第 7.5 节相同的自监督(self-supervision)或称自训练(self-training)算法:我们以一个文本语料库作为训练数据,在每个时间步 $t$ 要求模型预测下一个词。 之所以称这种模型为“自监督”,是因为我们无需为数据额外添加任何人工标注的标签——词序列本身的自然顺序就提供了监督信号! 我们只需训练模型,使其在预测训练序列中真实下一个词时的误差最小化,并使用交叉熵(cross-entropy)作为损失函数。 回忆一下,交叉熵损失衡量的是预测概率分布与真实分布之间的差异:
$$ L_{CE} = -\sum_{w \in V} \mathbf{y}_t[w] \log \hat{\mathbf{y}}_t[w] \tag{13.10} $$在语言建模任务中,真实分布 $\mathbf{y}_t$ 来源于已知的下一个词。 该分布表示为一个 one-hot 向量:对应真实下一个词的位置为 1,其余位置均为 0。 因此,语言建模的交叉熵损失实际上仅由模型赋予正确下一个词的概率决定。 在时刻 $t$,交叉熵损失即为模型对训练序列中下一个词所分配概率的负对数:
$$ L_{CE}(\hat{\mathbf{y}}_t, \mathbf{y}_t) = -\log \hat{\mathbf{y}}_t[w_{t+1}] \tag{13.11} $$因此,在输入序列的每个词位置 $t$,模型接收当前真实词 $w_t$ 和前一时刻的隐藏状态 $\mathbf{h}_{t-1}$ 作为输入。其中 $\mathbf{h}_{t-1}$ 编码了前面所有词 $w_{1:t-1}$ 的信息。 模型利用这些信息计算一个关于可能下一个词的概率分布,并据此计算对下一个词元 $w_{t+1}$ 的损失。 接着进入下一步:我们不使用模型上一步的预测结果,而是直接使用真实的词 $w_{t+1}$,连同之前的历史编码,来预测再下一个词 $w_{t+2}$ 的概率。 这种始终将正确的历史序列提供给模型以预测下一个词的做法(而不是将模型上一时刻的最佳预测结果作为输入),被称为教师强制(teacher forcing)。
网络中的权重通过梯度下降进行调整,以最小化整个训练序列上的平均交叉熵损失。 图 13.6 展示了这一训练流程。
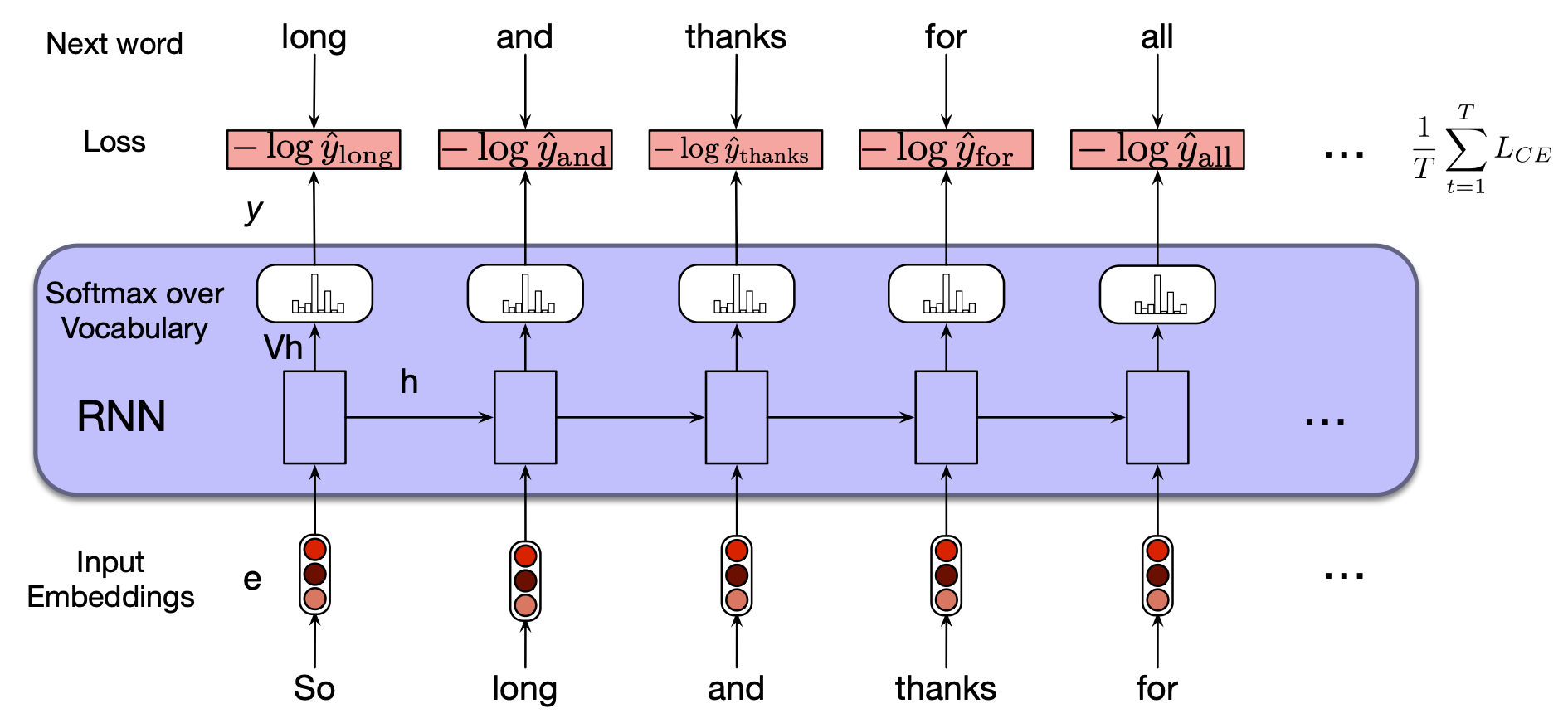
图 13.6 将 RNN 训练为语言模型的过程。
13.2.3 权重共享(Weight Tying)
细心的读者可能已经注意到,输入嵌入矩阵 $\mathbf{E}$ 与用于输出 softmax 的最后一层矩阵 $\mathbf{V}$ 非常相似。
$\mathbf{E}$ 的每一列表示词汇表中对应词在训练过程中学到的词嵌入。其目标是:语义和功能相近的词,其嵌入向量也应相近。 此外,在使用 RNN 进行语言建模时,我们通常假设嵌入维度与隐藏层维度相同(即模型维度 $d$)。因此,嵌入矩阵 $\mathbf{E}$ 的形状为 $[d \times |V|]$。 而最终层矩阵 $\mathbf{V}$ 的作用是:根据网络最后一层隐藏状态 $\mathbf{h}$ 中包含的信息,通过计算 $\mathbf{V} \mathbf{h}$,为词汇表中每个词打分,以评估其作为下一个词的可能性。 $\mathbf{V}$ 的形状为 $[|V| \times d]$。 也就是说,$\mathbf{V}$ 的每一行形状与 $\mathbf{E}$ 的列转置后一致。换言之,$\mathbf{V}$ 实际上提供了第二组学习得到的词嵌入。
为了避免维护两套独立的嵌入矩阵,语言模型通常只使用一个嵌入矩阵,同时用于输入层和 softmax 输出层。 具体做法是:不再使用独立的 $\mathbf{V}$,而是在计算开始时使用 $\mathbf{E}$,在结尾处使用其转置 $\mathbf{E}^\top$(因为 $\mathbf{V}$ 的形状正好是 $\mathbf{E}$ 的转置)。 在两个位置使用同一个矩阵(其中一个为转置形式)的做法,称为权重共享(weight tying)1。 采用权重共享后,RNN 语言模型的计算公式变为:
$$ \begin{align*} \mathbf{e}_t &= \mathbf{E} \mathbf{x}_t \tag{13.12} \\ \mathbf{h}_t &= g(\mathbf{U} \mathbf{h}_{t-1} + \mathbf{W} \mathbf{e}_t) \tag{13.13} \\ \hat{\mathbf{y}}_t &= \text{softmax}(\mathbf{E}^\top \mathbf{h}_t) \tag{13.14} \end{align*} $$这种方法不仅提升了模型的困惑度(perplexity)表现,还显著减少了模型所需的参数数量。
在 Transformer 模型中(第 9 章),我们也采用这种做法,通常将 $\mathbf{E}^\top$ 称为解嵌入矩阵(unembedding matrix)。 ↩︎