循环神经网络(RNN)是指网络连接中包含循环结构的任何网络。这意味着,某些单元的值会直接或间接地依赖于自身先前输出的结果作为输入。 这类网络虽然功能强大,但难以分析和训练。 然而,在循环网络这一大类中,存在一些受约束的架构。这些架构在处理语言任务时已被证明极为有效。 本节将讨论一类被称为Elman 网络(Elman, 1990)或简单循环网络的循环网络。 这类网络本身具有实用价值,同时也是更复杂方法的基础,例如本章后面将讨论的长短期记忆(LSTM)网络。 在本章中,当我们使用术语 RNN 时,特指这些结构更简单、约束更强的网络。(不过需要注意,在其他场合,“RNN”一词常被泛指任何具有循环特性的网络,包括 LSTM。)
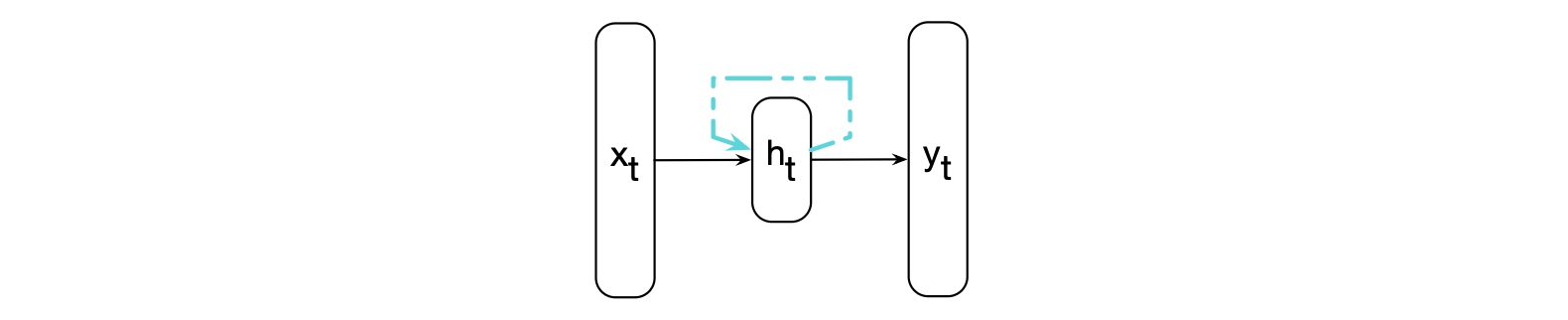
图 13.1 Elman(1990)提出的简单循环神经网络。 隐藏层的输入中包含一个循环连接。 也就是说,隐藏层的激活值既取决于当前输入,也取决于前一时刻隐藏层的激活值。
图 13.1 展示了 RNN 的结构。 与普通前馈网络类似,代表当前输入的向量 $\mathbf{x}_t$ 会先与一个权重矩阵相乘,再通过一个非线性激活函数,从而计算出隐藏单元层的值。 随后,该隐藏层用于计算对应的输出 $\mathbf{y}_t$。 与之前基于窗口的方法不同,RNN 按顺序逐个处理序列中的元素。 我们用下标表示时间,因此 $\mathbf{x}_t$ 表示时刻 $t$ 的输入向量。 与前馈网络的关键区别在于图中虚线所示的循环连接。 该连接将前一时刻隐藏层的值作为额外输入,加入到当前隐藏层的计算中。
前一时刻的隐藏层提供了一种记忆或上下文机制,它编码了之前的处理信息,并用于指导后续时刻的决策。 重要的是,这种方法对先前上下文的长度没有固定限制。前一隐藏层所包含的上下文信息,理论上可以回溯到序列的起始位置。
引入时间维度后,RNN 看似比非循环架构更复杂。 但实际上,两者差别并不大。 给定当前输入向量和前一时刻隐藏层的值,我们仍然执行第 6 章介绍的标准前馈计算。 为了说明这一点,请参考图 13.2。该图清晰地展示了循环的本质,以及它如何参与隐藏层的计算。 最重要的变化在于新增了一组权重 $\mathbf{U}$。这组权重从前一时刻的隐藏层连接到当前时刻的隐藏层。 它们决定了网络在计算当前输出时如何利用过去上下文的信息。 与网络中的其他权重一样,这些连接也通过反向传播进行训练。
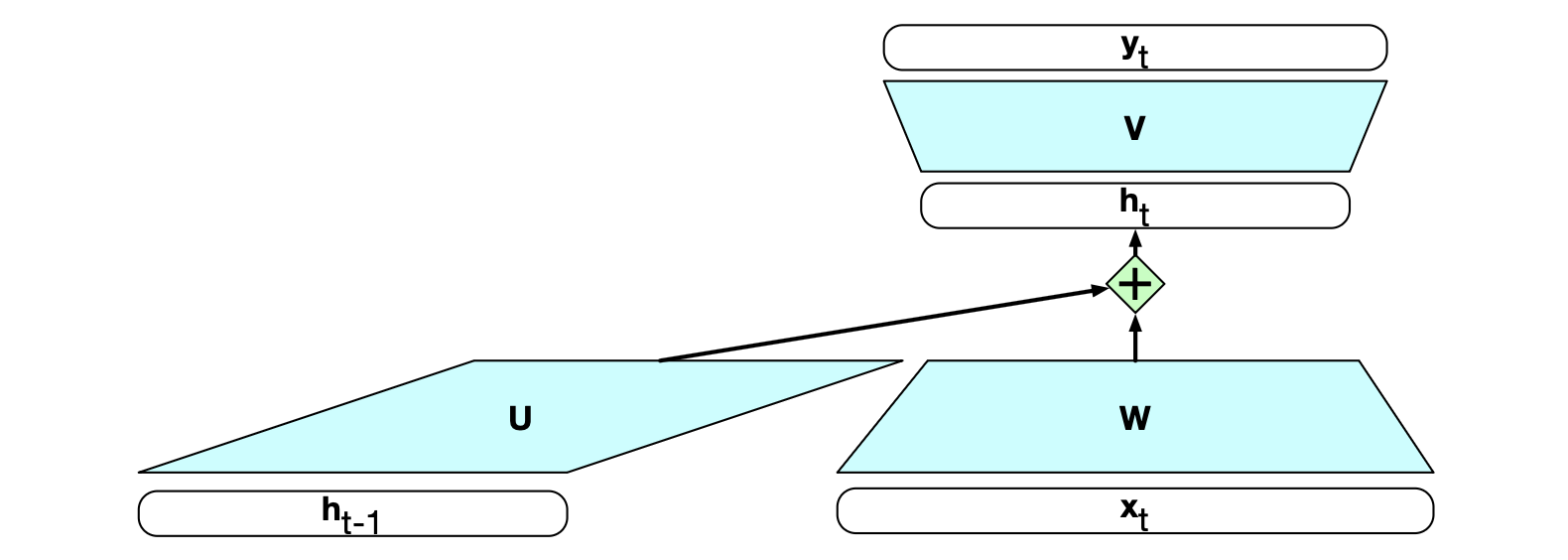
图 13.2 将简单循环神经网络表示为前馈网络的形式。 前一时刻的隐藏层 $\mathbf{h}_{t-1}$ 与权重矩阵 $\mathbf{U}$ 相乘,然后加到当前时刻的前馈部分上。
13.1.1 RNN 中的推理
RNN 中的前向推理(将输入序列映射为输出序列)与我们之前在前馈网络中看到的过程几乎完全相同。 要为输入 $\mathbf{x_t}$ 计算输出 $\mathbf{y_t}$,我们需要当前时刻隐藏层的激活值 $\mathbf{h}_t$。 为此,我们将输入 $\mathbf{x_t}$ 与权重矩阵 $\mathbf{W}$ 相乘,同时将前一时刻的隐藏层 $\mathbf{h}_{t-1}$ 与权重矩阵 $\mathbf{U}$ 相乘。 接着,将这两个结果相加,并通过一个合适的激活函数 $g$,得到当前隐藏层的激活值 $\mathbf{h}_t$。 一旦获得隐藏层的值,就可以像常规方法一样计算输出向量。
$$ \begin{align*} \mathbf{h}_t &= g(\mathbf{Uh}_{t-1} + \mathbf{Wx}_t) \tag{13.1} \\ \mathbf{y}_t &= f(\mathbf{Vh}_t) \tag{13.2} \end{align*} $$我们用 $d_{in}$、$d_h$ 和 $d_{out}$ 分别表示输入层、隐藏层和输出层的维度。 据此,三个参数矩阵分别为:$\mathbf{W} \in \mathbb{R}^{d_h \times d_{in}}$,$\mathbf{U} \in \mathbb{R}^{d_h \times d_h}$,$\mathbf{V} \in \mathbb{R}^{d_{out} \times d_h}$。
我们通过 softmax 计算得到 $y_t$,从而获得对所有可能输出类别的概率分布:
$$ \mathbf{y}_t = \text{softmax}(\mathbf{Vh}_t) \tag{13.3} $$由于时刻 $t$ 的计算依赖于时刻 $t-1$ 的隐藏层值,因此推理必须采用增量式算法:从序列起点逐步推进到终点,如图 13.3 所示。 简单循环网络的顺序特性也可以通过时间展开(unrolling)来体现,如图 13.4 所示。 在该图中,每个时间步都复制了各层单元,以表明它们在不同时刻具有不同的值。 但所有权重矩阵在时间上是共享的。
function FORWARD_RNN(x, network) returns output sequence y
h₀ ← 0
for i ← 1 to LENGTH(x) do
hᵢ ← g(U hᵢ₋₁ + W xᵢ)
yᵢ ← f(V hᵢ)
return y
图 13.3 简单循环网络中的前向推理过程。 矩阵 $\mathbf{U}$、$\mathbf{V}$ 和 $\mathbf{W}$ 在所有时间步共享;而每个时间步都会计算出新的 $\mathbf{h}$ 和 $\mathbf{y}$ 值。
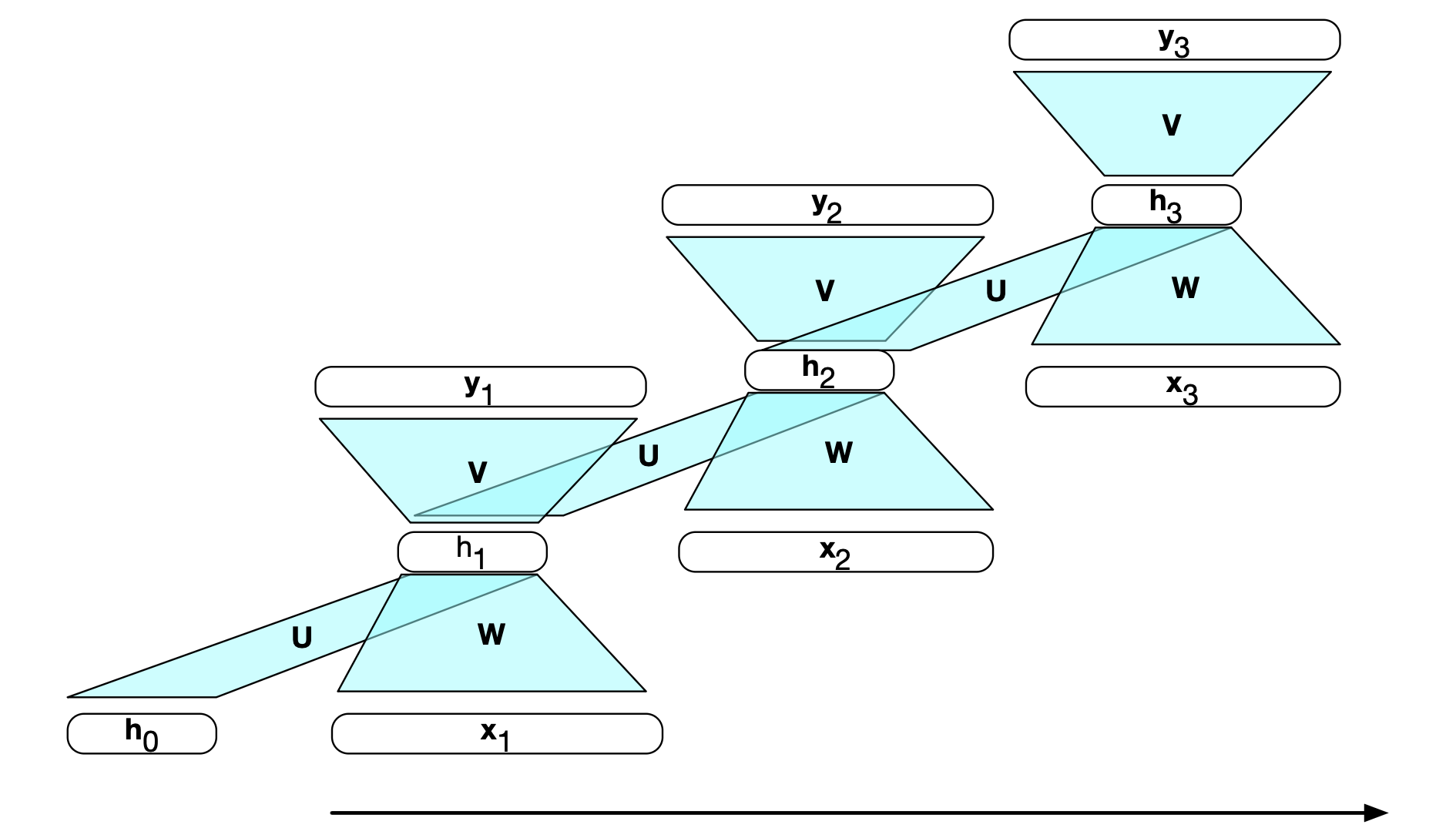
图 13.4 按时间展开的简单循环神经网络。 每个时间步都会重新计算网络各层,而权重矩阵 $\mathbf{U}$、$\mathbf{V}$ 和 $\mathbf{W}$ 在所有时间步之间共享。
13.1.2 训练
与前馈网络一样,我们使用训练集、损失函数和反向传播来计算梯度,从而调整循环网络中的权重。 如图 13.2 所示,我们现在需要更新三组权重:从输入层到隐藏层的权重 $\mathbf{W}$;从前一时刻隐藏层到当前隐藏层的权重 $\mathbf{U}$;从隐藏层到输出层的权重 $\mathbf{V}$。
图 13.4 突显了两个在前馈网络反向传播中无需考虑的问题。 第一,要计算时刻 $t$ 输出的损失函数,我们需要时刻 $t-1$ 的隐藏层值。 第二,时刻 $t$ 的隐藏层不仅影响当前时刻的输出,还会影响时刻 $t+1$ 的隐藏层(进而影响 $t+1$ 时刻的输出和损失)。 因此,要评估 $\mathbf{h}_t$ 所累积的误差,我们必须同时考虑它对当前输出以及后续所有输出的影响。
针对这种情况调整反向传播算法,会得到一个用于训练 RNN 权重的两阶段算法。 第一阶段是前向推理:依次计算每个时间步的 $\mathbf{h}_t$ 和 $\mathbf{y}_t$,累加每一步的损失,并保存每个时间步的隐藏层值,供下一步使用。 第二阶段是反向处理:从序列末尾开始逆序遍历,逐步计算所需的梯度,并为每个时间步保存误差项,以用于前一时间步隐藏层的梯度计算。 这种通用方法通常被称为随时间反向传播(Backpropagation Through Time, BPTT)(Werbos 1974;Rumelhart 等 1986;Werbos 1990)。
幸运的是,在现代计算框架和充足计算资源的支持下,我们不再需要为 RNN 训练设计专门的算法。 如图 13.4 所示,只要将循环网络显式地按时间展开为一个前馈计算图,就能消除所有显式的循环结构,从而直接使用标准反向传播训练网络权重。 在这种方法中,我们提供一个模板,定义网络的基本结构,包括输入层、隐藏层和输出层所需的所有参数、权重矩阵,以及所用的激活函数和输出函数。 当给定一个具体的输入序列时,系统会根据该序列生成一个展开的前馈网络,并利用该计算图执行前向推理或通过普通反向传播进行训练。
对于涉及很长输入序列的应用(例如语音识别、字符级处理或流式连续输入),完整展开整个序列可能不可行。 此时,我们可以将输入序列切分为若干固定长度的可管理片段,并将每个片段视为一个独立的训练样本。