翻译质量通常从两个维度进行评估:
- 充分性(adequacy):译文在多大程度上准确传达了源句的完整含义。有时也称为忠实度(faithfulness)或保真度(fidelity)。
- 流畅度(fluency):译文在目标语言中是否流畅(是否符合语法、清晰、可读、自然)。
使用人工评估最为准确,但出于便利性考虑,自动评估指标也被广泛采用。
12.6.1 使用人工评分者评估机器翻译
最准确的评估方法是依靠人工评分者(例如在线众包工作者)对每条译文从上述两个维度进行打分。
例如,在流畅度维度上,我们可以询问评分者:机器翻译输出(即目标文本)在多大程度上是可理解的、清晰的、易读的或自然的。 我们可以提供一个评分量表,比如从 1(完全不可理解)到 5(完全可理解),或从 1 到 100,要求评分者对每句或每段译文进行打分。
同样地,我们也可以用类似方式评估第二个维度——充分性。 如果评分者具备双语能力,我们可以同时向其展示源句和机器生成的译文,并请他们在 5 分制或 100 分制量表上评估:源句中的信息有多少被保留在了译文中。 如果只有单语评分者,但手头有高质量的人工参考译文,那么我们可以将参考译文与机器译文一并交给他们,让他们评估两者在信息保留方面的相似程度。 另一种做法是进行排序(ranking):向评分者提供一对候选译文,让他们选择更优的一个。
对人工评分者(通常是在线众包人员)进行培训至关重要。 缺乏翻译经验的评分者往往难以区分流畅度与充分性,因此培训内容通常包括精心设计的示例,明确区分这两个概念。 此外,评分者之间常常存在分歧——源句本身可能存在歧义,评分者的背景知识不同,或对评分尺度的理解不一致。 因此,通常会剔除异常评分者,并且(如果使用了足够细粒度的评分尺度)对每位评分者的打分进行标准化处理:将其每个分数减去该评分者自身的平均分,再除以其评分的标准差。
如前所述,使用人工评分者的另一种方式是让他们对译文进行译后编辑(post-editing):即在机器翻译输出的基础上进行最小限度的修改,直到他们认为该译文已正确表达了原意。 随后,可通过比较译后编辑结果与原始机器译文之间的差异来衡量翻译质量。
12.6.2 自动评估
尽管人类对机器翻译输出的评估最为可靠,但人工评估往往耗时且成本高昂。 因此,自动评估指标常被用作临时替代方案。 虽然自动指标的准确性低于人工评估,但它们有助于快速测试系统改进的效果,甚至可作为训练过程中的自动损失函数。 本节将介绍两类主流自动评估指标:基于字符或词重叠的指标,以及基于嵌入相似度的指标。
基于字符重叠的自动评估:chrF
机器翻译评估中最简单且最健壮的指标之一是 chrF(character F-score,字符 F 分数)(Popović, 2015)。 chrF(以及许多早期相关指标,如 BLEU、METEOR、TER 等)基于 Miller 和 Beebe-Center(1956)开创性工作中的一个朴素思想:好的机器翻译结果往往会包含与人工译文相同的字符和词语。 考虑一个来自平行语料库的测试集,其中每个源句都配有一条人工参考译文(gold human translation)和一条待评估的机器翻译候选译文。 chrF 指标通过计算候选译文与参考译文之间字符 n-gram 的重叠程度,为每条机器翻译结果打分。
给定一个假设译文(hypothesis)和一条参考译文(reference),chrF 接受一个参数 $k$,表示要考虑的字符 n-gram 的最大长度,并分别计算前 $k$ 种 n-gram(从 1-gram 到 k-gram)的平均精确率(precision)和平均召回率(recall):
- chrP:假设译文中字符 1-gram、2-gram、…、k-gram 出现在参考译文中的比例的平均值;
- chrR:参考译文中字符 1-gram、2-gram、…、k-gram 出现在假设译文中的比例的平均值。
随后,chrF 使用加权 F 分数结合 chrP 和 chrR,权重由参数 $\beta$ 控制。 通常设 $\beta = 2$,即召回率的权重是精确率的两倍:
$$ \text{chrF}_\beta = (1 + \beta^2) \frac{\text{chrP} \cdot \text{chrR}}{\beta^2 \cdot \text{chrP} + \text{chrR}} \tag{12.20} $$当 $\beta = 2$ 时,公式简化为:
$$ \text{chrF}_2 = \frac{5 \cdot \text{chrP} \cdot \text{chrR}}{4 \cdot \text{chrP} + \text{chrR}} $$例如,考虑以下两条假设译文,需针对参考译文 witness for the past 进行评分。 以下是假设译文及其在参数 $k = 2$、$\beta = 2$ 下计算出的 chrF 值(实际应用中,$k$ 通常取更大的值,如 6):
| REF: | witness for the past, | |
| HYP1: | witness of the past, | chrF2,2 = .86 |
| HYP2: | past witness | chrF2,2 = .62 |
我们来看 HYP1 的 chrF 值是如何计算的(HYP2 的计算留作读者练习)。 首先,chrF 忽略空格,因此先从参考译文和假设译文中移除所有空格:
| REF: | witnessforthepast, | (18 个 unigram,17 个 bigram) |
| HYP1: | witnessofthepast, | (17 个 unigram,16 个 bigram) |
接着统计参考译文与假设译文之间匹配的 unigram 和 bigram 数量:
| 匹配的 unigram: | w i t n e s s f o t h e p a s t , | (共 17 个) |
| 匹配的 bigram: | wi it tn ne es ss th he ep pa as st t | (共 13 个) |
据此计算 unigram 和 bigram 的精确率与召回率:
| P | R | |
|---|---|---|
| unigram | 17/17 = 1 | 17/18 = .944 |
| bigram | 13/16 = .813 | 13/17 = .765 |
然后取平均值得到 chrP 和 chrR:
$$ \begin{align*} chrP &= (17/17 +13/16)/2 = .906 \\ chrR &= (17/18 +13/17)/2 = .855 \\ chrF2,2 &= 5 \frac{\text{chrP} * \text{chrR}}{4\text{chrP} + \text{chrR}} = .86 \end{align*} $$chrF 算法简单、健壮,并且在多种语言上与人类判断高度相关(Kocmi et al., 2021)。
替代性重叠指标:BLEU
除了 chrF,还存在多种其他基于重叠的评估指标。例如,在 chrF 出现之前,人们常使用一种基于词的重叠指标——BLEU(Bilingual Evaluation Understudy,双语评估替补)(Papineni et al., 2002)。与 chrF 不同,BLEU 仅基于精确率(precision),而不结合召回率。 BLEU 对一组候选译文的打分由两部分构成:一是所有句子上n-gram 词精确率的综合度量,二是对整个语料库计算的一个简洁性惩罚(brevity penalty),用于惩罚过短的译文。
那么,什么是 n-gram 精确率? 以仅包含一个句子的语料库为例。 unigram 精确率指候选译文中出现在参考译文中的 unigram 词元所占的百分比;bigram、trigram 等依此类推,通常计算到 4-gram。 BLEU 将这一思路扩展到整个语料库:分子是所有句子中在参考译文中出现过的各类 n-gram 的总出现次数,分母是候选译文中所有 n-gram 的总出现次数。 对 unigram 到 4-gram 分别计算精确率后,取其几何平均值。 此外,BLEU 还包含若干复杂机制,例如简洁性惩罚(brevity penalty)用于惩罚候选译文整体过短;以某种特定方式执行 n-gram 计数截断(clipping),这是为避免重复词人为抬高分数,每个 n-gram 在参考译文中的出现次数上限被设为其在参考译文中实际出现的最大频次。
由于 BLEU 是基于词(word-based)的指标,它对词元化(tokenization)极为敏感。如果不同系统采用不同的分词标准,就无法公平比较其 BLEU 分数。此外,BLEU 在形态复杂的语言(如芬兰语、阿拉伯语)中表现较差。 尽管如此,BLEU 仍时有使用,尤其是在英译任务中。 此时,务必使用能强制统一分词标准的工具包,例如 SacreBLEU(Post, 2018)。
机器翻译评估中的统计显著性检验
chrF、BLEU 等基于字符或词重叠的自动指标主要用于比较两个系统,以回答诸如“我们刚提出的新算法是否真正提升了 MT 系统性能?”之类的问题。 要判断两个 MT 系统的 chrF 分数差异是否具有统计显著性,通常采用配对自助法(paired bootstrap test)或类似的随机化检验(randomization test)。
若想为单个系统的 chrF 分数计算置信区间,可按第 4.11 节所述方法操作:从原始测试集(或开发集)中有放回地重复抽样,生成数千个伪测试集。 然后分别计算每个伪测试集上的 chrF 分数。 若剔除得分最高的 2.5% 和最低的 2.5%,剩余分数即构成该系统 chrF 分数的 95% 置信区间。
若要比较系统 A 与系统 B,则对同一组伪测试集分别计算两者的 chrF 分数,并统计其中 A 分数高于 B 的比例。
chrF 的局限性
尽管 chrF、BLEU 等自动重叠指标十分实用,但它们也存在重要局限。 chrF 局部性过强:若一个长语段在译文中被移动位置,chrF 分数可能几乎不变。 无法评估跨句特性:chrF 无法衡量译文在篇章层面的质量,如话语连贯性(discourse coherence)(见第 24 章)。 系统间比较能力有限:当比较本质不同的系统时(例如人机协作翻译 vs 纯机器翻译,或不同架构的 MT 模型),chrF 等指标往往表现不佳(Callison-Burch et al., 2006)。 因此,chrF 等自动重叠指标最适合用于评估同一系统内部的改进。
12.6.3 自动评估:基于嵌入的方法
chrF 指标通过衡量人工参考译文与候选机器译文之间完全匹配的字符 n-gram 来评估质量。 然而,这一标准过于严格——因为一个好的译文可能使用了同义词、近义表达或意译(paraphrase),而非逐字对应。 早期指标如 METEOR(Banerjee and Lavie, 2005)率先提出了一种解决方案:允许参考译文 $x$ 与候选译文 $\tilde{x}$ 中的同义词(synonyms)相互匹配。而更近期的指标则利用 BERT 或其他上下文嵌入来实现这一思想。
例如,在某些场景下,我们可能拥有包含人工翻译质量评分的数据集。 这类数据集由三元组 $(x, \tilde{x}, r)$ 构成,其中 $x = (x_1, \dots, x_n)$ 是参考译文,$\tilde{x} = (\tilde{x}_1, \dots, \tilde{x}_m)$ 是候选机器译文,$r \in \mathbb{R}$ 是人类评分者给出的分数,表示 $\tilde{x}$ 相对于 $x$ 的翻译质量。 基于此类数据,像 COMET(Rei et al., 2020)和 BLEURT(Sellam et al., 2020)这样的方法会训练一个预测器:将 $x$ 和 $\tilde{x}$ 输入一个经过额外预训练并针对人工评分数据微调过的 BERT 变体,再接一个线性层,用于预测人类评分 $r$。 这类模型的输出与人类评分高度相关。
然而,在另一些情况下,我们并没有带有人工评分的数据。 此时,我们可以直接通过参考译文与候选译文的嵌入相似度来衡量其质量。 以 BERTScore 算法(Zhang et al., 2020)为例(见图 12.11),该方法将参考译文 $x$ 和候选译文 $\tilde{x}$ 分别输入 BERT,为每个词元 $x_i$ 和 $\tilde{x}_j$ 生成上下文嵌入向量。 然后,对每一对词元 $(x_i, \tilde{x}_j)$,计算其余弦相似度:
$$ \frac{x_i \cdot \tilde{x}_j}{\|x_i\| \, \|\tilde{x}_j\|} $$参考译文 $x$ 中的每个词元 $x_i$ 匹配到候选译文 $\tilde{x}$ 中的词元,从而计算召回率;将候选译文 $\tilde{x}$ 中的每个词元 $\tilde{x}_j$ 匹配到参考译文 $x$ 中的词元,从而计算精确率(每个词元贪婪地匹配对应句子中最相似的词元)。 最终,BERTScore 定义如下形式的精确率与召回率(从而可导出 F₁ 分数):
$$ \begin{align*} R_{\text{BERT}} &= \frac{1}{|x|} \sum_{x_i \in x} \max_{\tilde{x}_j \in \tilde{x}} \, \cos(x_i, \tilde{x}_j) \\ P_{\text{BERT}} &= \frac{1}{|\tilde{x}|} \sum_{\tilde{x}_j \in \tilde{x}} \max_{x_i \in x} \, \cos(x_i, \tilde{x}_j) \tag{12.21} \end{align*} $$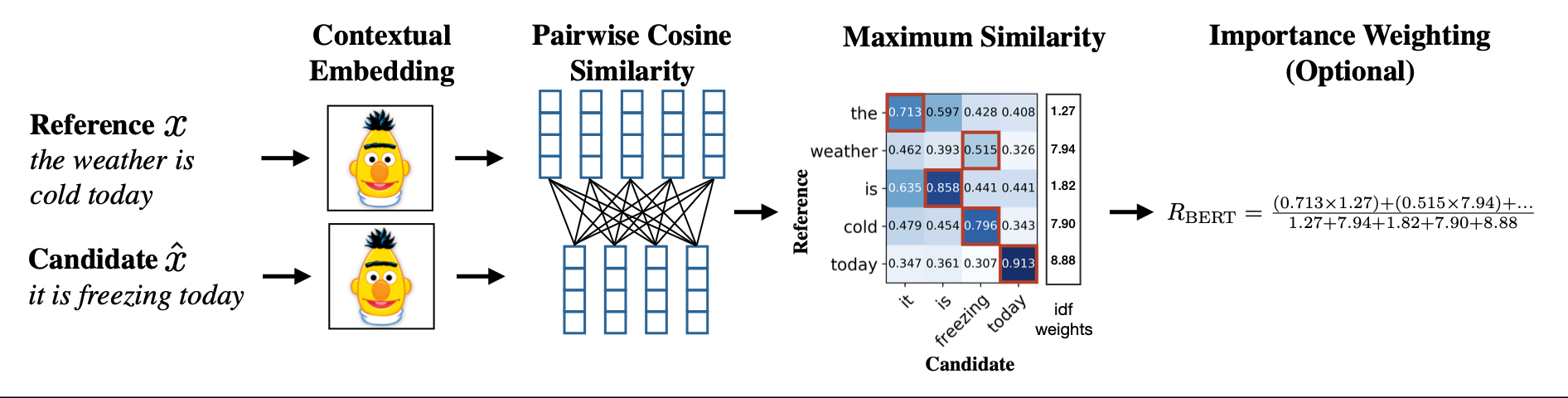
图 12.11 BERTScore 召回率的计算过程(参考译文 $x$ 与候选译文 $\tilde{x}$),引自 Zhang et al. (2020) 图 1。 此图展示的是该指标的一个扩展版本,其中每个词元还根据其 IDF(逆文档频率)值进行了加权,以降低常见词的影响。