回顾第 8 章介绍的贪心解码(greedy decoding)算法:在生成过程的每个时间步 $t$,输出 $y_t$ 通过计算词汇表中每个词的概率并选择概率最高的词(即取 argmax)来确定:
$$ \hat{w}_t = \text{argmax}_{w \in V} \, P(w \mid \mathbf{w}_{< t}) \tag{12.14} $$贪心解码的问题在于,在时间步 $t$ 看似概率最高的词,到了时间步 $t+1$ 之后可能被证明是错误的选择。 束搜索(beam search)算法通过保留多个候选序列直到后续步骤再决定最优者,从而缓解这一问题。
在束搜索中,我们将解码建模为在所有可能生成序列的空间中进行搜索。该空间表示为一棵搜索树(search tree),其中分支(branches)代表动作(即生成一个词元),节点(nodes)代表状态(即已生成某个特定前缀)。 我们的目标是找到最优的动作序列,也就是具有最高整体概率的字符串。
问题示例说明
图 12.7 展示了一个虚构的例子。 全局概率最高的序列是 ok ok EOS(其概率为 $0.4 \times 0.7 \times 1.0 = 0.28$)。 但贪心搜索无法找到它,因为它在第一步错误地选择了 yes,因为 yes 在局部具有最高概率(0.5)。
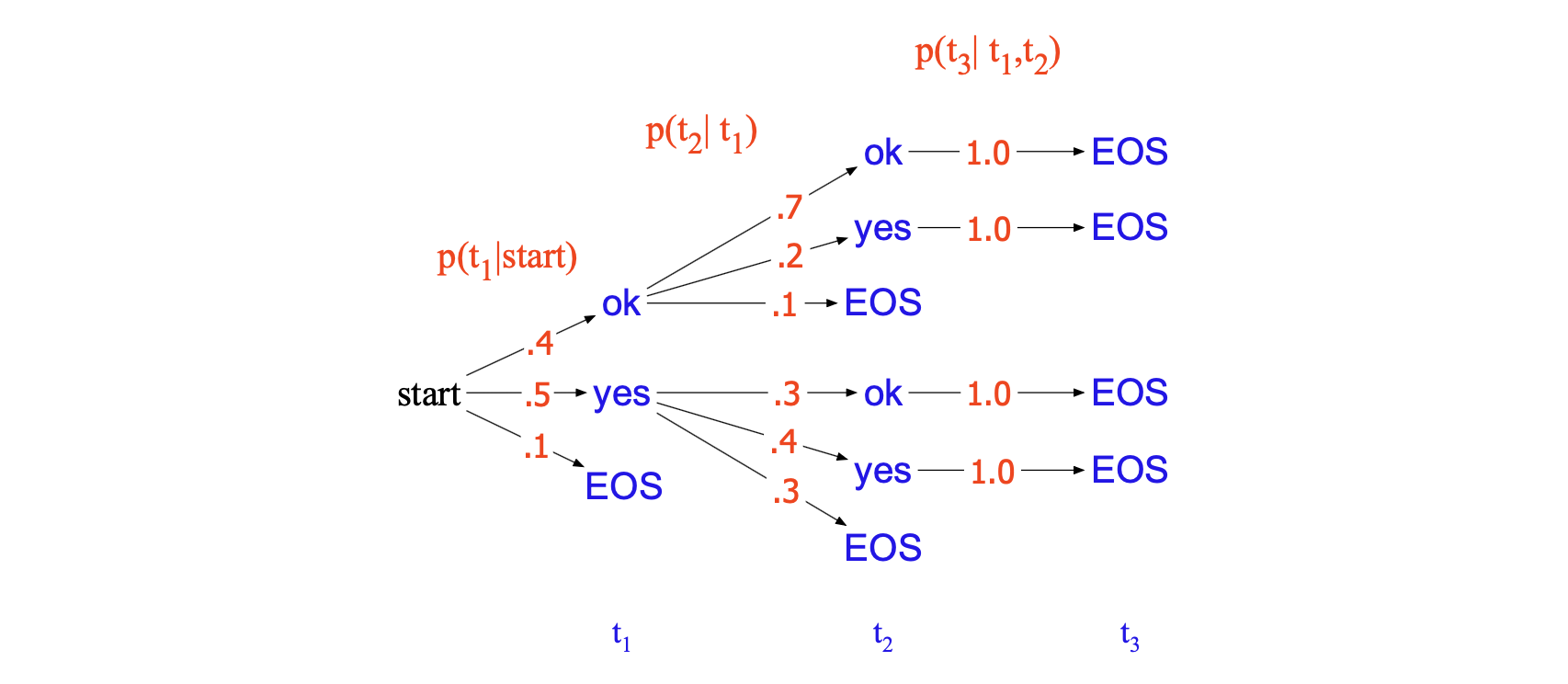
图 12.7 从词汇表 $V = \{\text{yes}, \text{ok}, \text{EOS}\}$ 中生成目标序列 $T = t_1, t_2, \dots$ 的搜索树,图中标注了从每个状态生成各词元的概率。 贪心搜索会选择 yes 后接 yes,而非全局概率最高的序列 ok ok。
对于某些任务(如第 17 或 18 章将讨论的词性标注或句法分析),我们可以使用动态规划搜索(例如维特比算法)来解决此类问题。 然而,动态规划不适用于输出决策之间存在长距离依赖的生成任务。 唯一能保证找到最优解的方法是穷举搜索:计算所有 $V^T$ 个可能句子(对某个长度 $T$ 而言)的概率,但这显然计算代价过高,无法实际应用。
解决方案:束搜索
因此,机器翻译系统通常采用束搜索(beam search)进行解码,这是一种由 Lowerre(1976)首次提出的启发式搜索方法。 在束搜索中,我们不再在每个时间步只选择概率最高的单个词元,而是保留 $k$ 个可能的候选词元。 这个固定大小的内存占用 $k$ 被称为束宽(beam width),其名称源于手电筒光束的隐喻——光束可以调节得更宽或更窄。
在解码的第一步,我们对整个词汇表计算 softmax,为每个词分配一个概率,然后从中选出概率最高的 $k$ 个选项。 这 $k$ 个初始输出构成当前的搜索前沿(search frontier),这些初始词序列被称为假设(hypotheses)。 每个假设是一个部分生成的输出序列(即“到目前为止的翻译”)及其对应的概率。
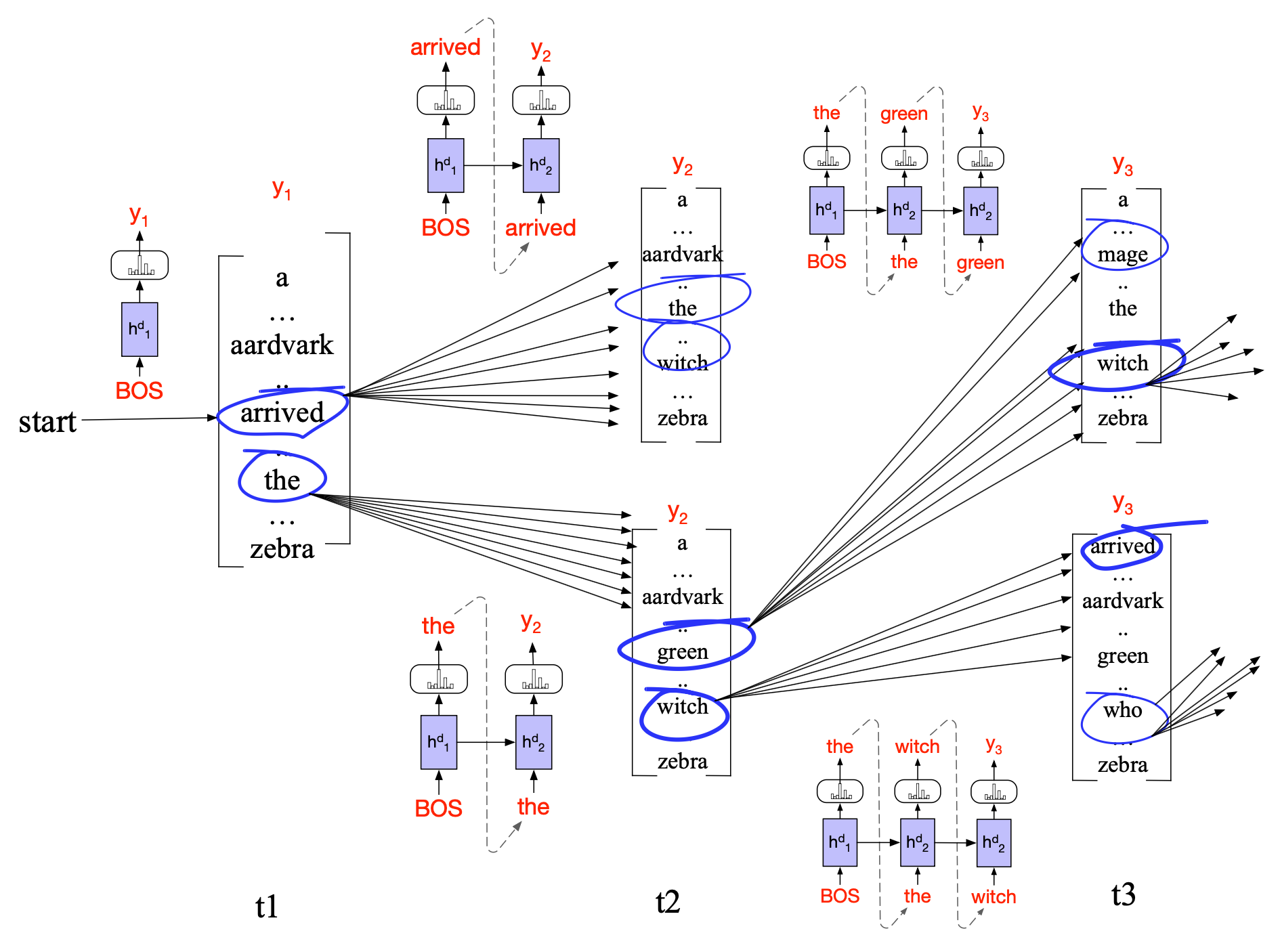
图 12.8 束宽 $k = 2$ 的束搜索解码过程。 在每个时间步,我们从当前前沿中选择 $k$ 个最佳假设,对每个假设生成 $V$ 种可能的扩展,对总共 $k \times V$ 个新假设进行评分,并保留其中最好的 $k = 2$ 个继续下一步。 在时间步 1,前沿包含从初始解码器状态中选出的两个最佳选项:“arrived” 和 “the”。 我们将它们分别扩展,计算所有新假设(“arrived the”、“arrived aardvark”、“the green”、“the witch”)的概率,并再次选出最好的两个(“the green” 和 “the witch”)作为新的搜索前沿。 图中弧线上的图像示意了每一步为评分下一个词所需运行的多个解码器(为简化起见,未画出交叉注意力部分)。
在后续步骤中,当前前沿中的每个假设都会被送入独立的解码器进行扩展,每个解码器对整个词汇表生成 softmax 分布,从而为该假设生成所有可能的下一个词元。 这 $k \times V$ 个新假设根据条件概率 $P(y_i \mid x, y_{< i})$ 进行评分——即当前词选择的概率乘以到达该路径的累积概率。 随后,我们从这 $k \times V$ 个假设中剪枝,仅保留得分最高的 $k$ 个,确保搜索前沿始终不超过 $k$ 个假设,也最多只运行 $k$ 个解码器。 图 12.8 以句子 “The green witch arrived” 的开头为例,展示了束宽为 2 的束搜索过程。
这一过程持续进行,直到某个假设生成了 EOS(结束符),表明已找到一个完整的候选输出。 此时,该已完成的假设会从前沿中移除,束宽相应减 1。 搜索继续进行,直到束宽减至 0,最终得到 $k$ 个完成的假设。
为了用对数概率对每个节点评分,我们利用概率的链式法则将 $P(y \mid x)$ 分解为每个词在其上下文条件下概率的乘积,并将其转换为对数之和(对于长度为 $t$ 的输出序列):
$$ \begin{align*} \text{score}(y) &= \log P(y \mid x) \\ &= \log\big(P(y_1 \mid x) P(y_2 \mid y_1, x) P(y_3 \mid y_1, y_2, x) \cdots P(y_t \mid y_1, \dots, y_{t-1}, x)\big) \\ &= \sum_{i=1}^{t} \log P(y_i \mid y_1, \dots, y_{i-1}, x) \tag{12.15} \end{align*} $$因此,在每一步,只需将当前前缀序列的累计对数概率与生成下一个词元的对数概率相加,即可得到新部分序列的概率。 图 12.9 展示了图 12.8 中示例句子的评分过程,使用了一些简化的虚构概率值。 注意:对数概率为负数或零,两个对数概率中较大的那个(即更接近 0 的)代表更高的原始概率。
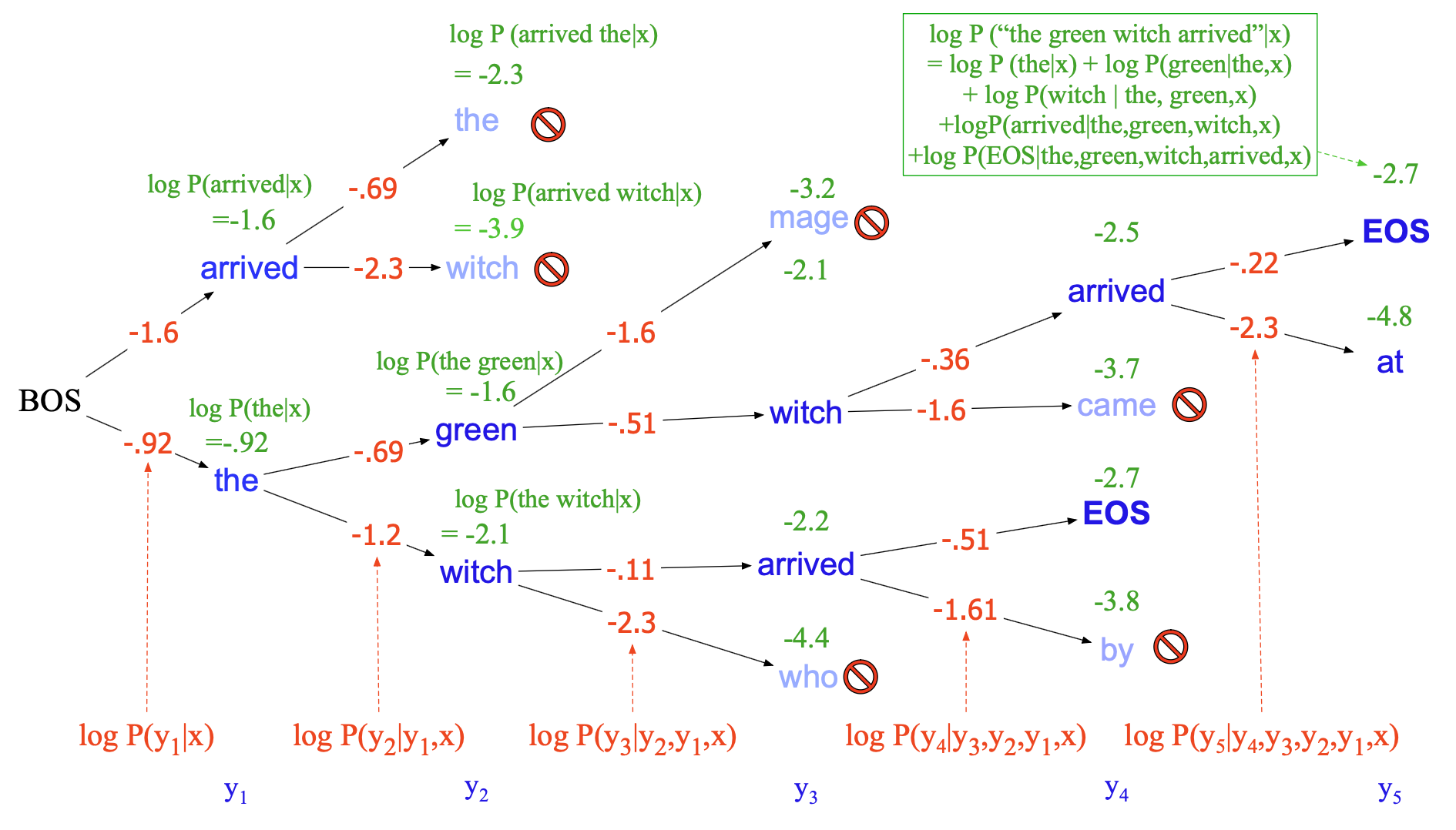
图 12.9 束宽 $k = 2$ 的束搜索评分过程。 我们在束中维护每个假设的对数概率,通过逐步累加生成每个后续词元的对数概率来更新。 只有得分最高的 $k$ 条路径会被扩展到下一步。
function BEAM DECODE (c, beam width) returns best paths
y_0, h_0 ← 0
path ← ()
complete paths ← ()
state ← (c, y₀, h₀, path) ;initial state
frontier ← ⟨state⟩ ;initial frontier
while frontier contains incomplete paths and beamwidth > 0
extended_frontier ← ⟨⟩
for each state ∈ frontier do
y ← DECODE (state)
for each word i ∈ Vocabularydo
successor ← NEWSTATE(state, i, y_i)
extended_frontier ← ADDTOBEAM (successor, extended_frontier, beam_width)
for each state in extended_frontier do
if state is complete do
complete_paths ← APPEND (complete_paths, state)
extended_frontier ← REMOVE (extended_frontier, state)
beam_width ← beam_width - 1
frontier ← extended_frontier
return completed_paths
function NEWSTATE(state, word, word_prob) returns new state
function ADDTOBEAM (state, frontier, width) returns updated frontier
if LENGTH (frontier) < width then
frontier ← INSERT (state, frontier)
else if SCORE (state) > SCORE (WORST OF(frontier))
frontier ← REMOVE (WORST OF(frontier))
frontier ← INSERT (state, frontier)
return frontier
图 12.10 束搜索解码算法。
图 12.10 给出了完整的算法。 该版本的一个问题是,完成的假设可能具有不同长度。 由于语言模型通常会给较长的序列分配更低的概率,朴素的算法会倾向于选择较短的输出 $y$。(在解码早期阶段这不是问题,因为束搜索是广度优先的,所有被比较的假设长度相同。)因此,我们通常采用长度归一化(length normalization)方法,例如将对数概率除以词数:
$$ \begin{align*} \text{score}(y) &= \frac{1}{t} \log P(y \mid x) \\ &= \frac{1}{t} \sum_{i=1}^{t} \log P(y_i \mid y_1, \dots, y_{i-1}, x) \tag{12.16} \end{align*} $$在机器翻译中,束宽 $k$ 通常设为 5 到 10 之间,最终会得到 $k$ 个候选翻译。 我们可以将这 $k$ 个结果连同各自的得分一并传递给下游应用;如果只需要一个翻译,则可选择概率最高的那个假设。
12.4.1 最小贝叶斯风险解码
最小贝叶斯风险(Minimum Bayes Risk,简称 MBR)解码是一种替代性解码算法,其效果有时甚至优于束搜索,也通常优于第 7.4 节介绍的其他解码方法(如温度采样)。
最小贝叶斯风险的核心思想是:我们不再选择概率最高的翻译,而是选择预期错误最少的翻译。 例如,我们可能希望解码算法找到在某种评估指标上得分最高的翻译。 在第 12.6 节中,我们将介绍诸如 chrF 或 BERTScore 等指标,它们用于衡量候选翻译与一组人工参考译文之间的匹配程度。 即使某个翻译在我们当前的概率模型下并非最可能的,只要它在这些指标上得分很高——尤其是在假设有大量高质量人工参考译文的情况下——它很可能是一个更优的翻译(即具有最小风险)。
在实际应用中,我们并不知道某个句子对应的所有理想译文集合。 因此,MBR 解码算法通常采用一种简化策略:从一组候选翻译中,选出与其他候选翻译整体最相似(根据某种匹配度量)的那个作为最终输出。 本质上,这是用一个较小的候选翻译集合 $\mathcal{Y}$ 来近似所有可能翻译的巨大空间 $\mathcal{U}$。
给定这个候选翻译集合 $\mathcal{Y}$ 以及某个相似度或对齐函数,我们选择最优翻译 $\hat{y}$ 为与集合中所有其他候选翻译总体最相似的那个:
$$ \hat{y} = \underset{y \in \mathcal{Y}}{\mathrm{argmax}} \sum_{c \in \mathcal{Y}} \text{util}(y, c) \tag{12.17} $$这个功能函数有多种,例如 chrF、BERTScore 或 BLEU。 候选翻译集合可通过第 7.4 节中的基本采样方法(如温度采样)生成;实验表明,即使仅使用 32 或 64 个候选翻译,也能取得良好效果。
最小贝叶斯风险解码也可用于其他自然语言处理任务。事实上,在被应用于机器翻译之前(Kumar and Byrne, 2004),它已在语音识别领域得到广泛应用(Stolcke et al., 1997;Goel and Byrne, 2000)。近年来的研究还表明,MBR 在多种生成任务中均表现优异,例如文本摘要、对话生成和图像描述生成(Suzgun et al., 2023a)。