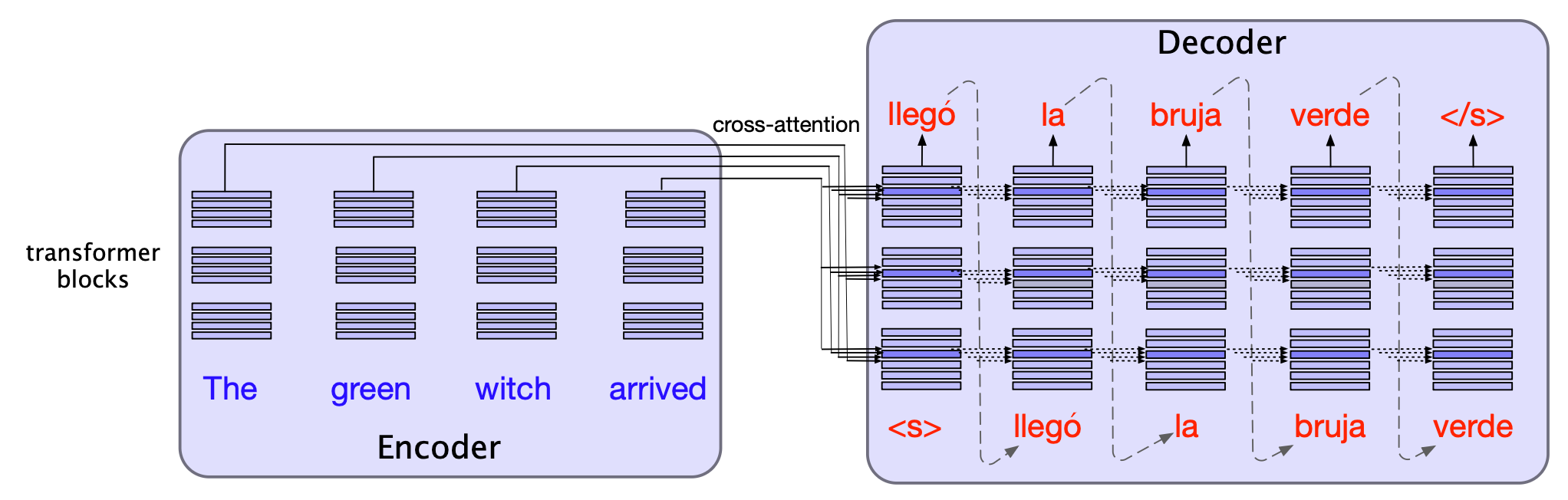
图 12.5 用于机器翻译的编码器-解码器 Transformer 架构。 编码器使用的是我们在第 8 章见过的 Transformer 模块,而解码器则使用一种更强大的模块,其中增加了一个额外的交叉注意力(cross-attention)层,可以关注编码器中的所有词。 我们将在下一节更详细地介绍这一点。
机器翻译的标准架构是编码器-解码器 Transformer。 图 12.5 在较高层次上展示了该架构的基本思路。 可以看到,编码器-解码器架构由两个 Transformer 组成:一个编码器,与第 8 章介绍的基础 Transformer 相同;以及一个解码器,它增加了一个特殊的交叉注意力(cross-attention)层。 编码器接收源语言的输入词元序列 $\mathbf{X} = \mathbf{x}_1, \dots, \mathbf{x}_n$,并通过若干编码器模块将其映射为输出表示 $\mathbf{H}_{enc} = \mathbf{h}_1, \dots, \mathbf{h}_n$。
解码器本质上是一个条件语言模型,关注编码器的表示逐个生成目标词,它在每个时间步基于源句子和此前已生成的目标语言词来生成下一个词元。 解码过程可以采用第 8 章讨论的任意解码方法,例如贪心搜索、温度采样或核采样。但在机器翻译中,最常用的解码算法是束搜索(beam search),我们将在第 12.4 节介绍。
不过,该架构的组件与我们之前见过的 Transformer 模块略有不同。 首先,为了能够关注源语言,解码器中的 Transformer 模块增加了一个额外的交叉注意力层。 回顾第 8 章的 Transformer 模块:它包含一个自注意力层(关注来自前一层的输入),前面接一个层归一化(layer norm),后面再接另一个层归一化和前馈网络。 而解码器的 Transformer 模块在此基础上增加了一层特殊类型的注意力——交叉注意力(有时也称为编码器-解码器注意力或源注意力)。 交叉注意力的形式与普通 Transformer 模块中的多头注意力相同,区别在于:其查询(queries)一如既往来自解码器的前一层,而键(keys)和值(values)则来自编码器的输出。
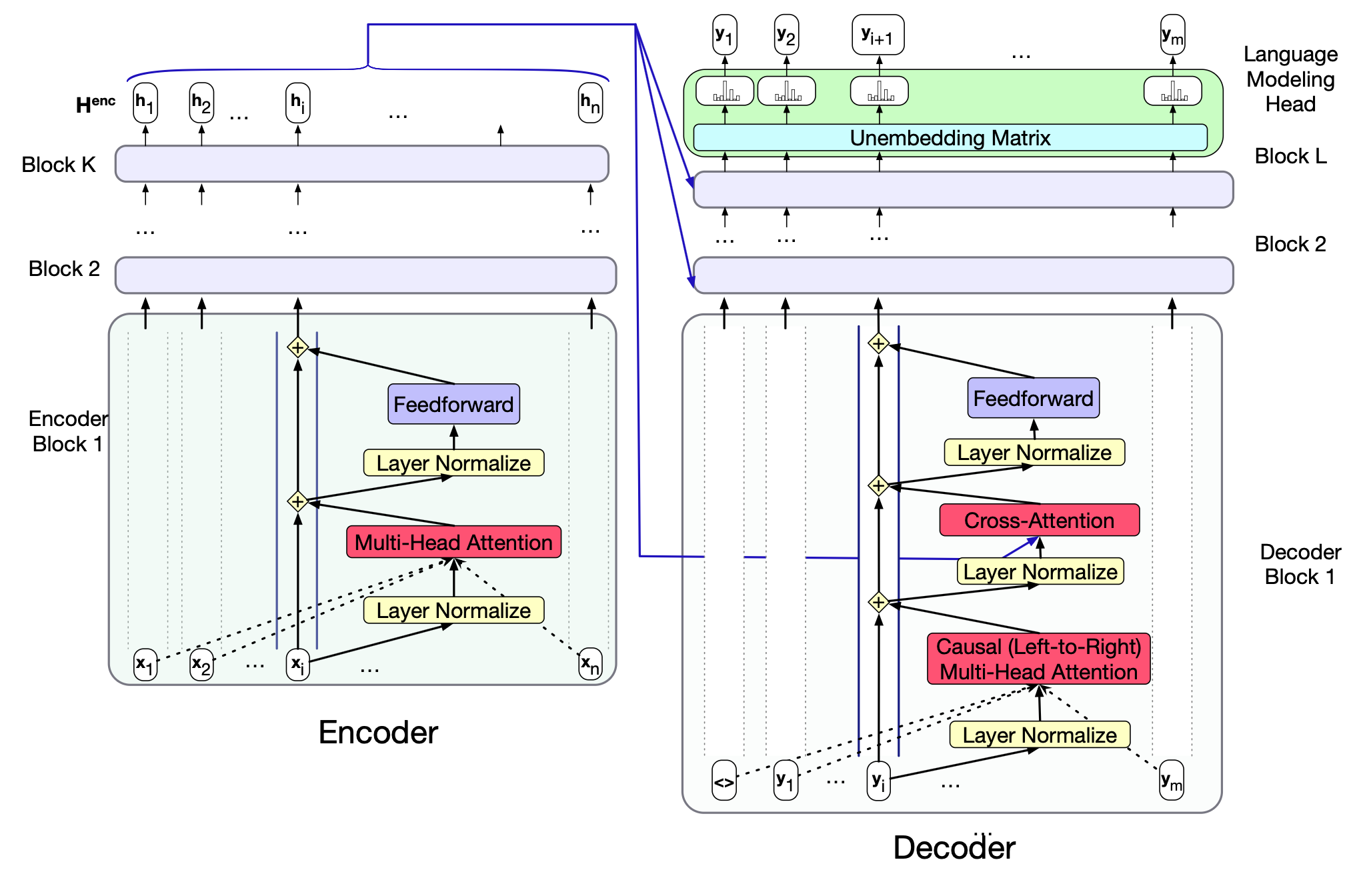
图 12.6 编码器与解码器的 Transformer 模块,以残差流视角展示。 编码器的最终输出 $\mathbf{H}_{enc} = \mathbf{h_1}, \dots, \mathbf{h}_n$ 作为上下文被送入解码器。 解码器本质上是一个标准的 Transformer,只是多了一个交叉注意力层,该层接收编码器的输出 $\mathbf{H}_{enc}$,并用它来构造自身的键($\mathbf{K}$)和值($\mathbf{V}$)输入。
也就是说,在标准的多头注意力中,每个注意力层的输入是 $\mathbf{X}$,而在交叉注意力中,输入则是编码器的最终输出 $\mathbf{H}_{enc} = \mathbf{h}_1, \dots, \mathbf{h}_n$。 $\mathbf{H}_{enc}$ 的形状为 $[n \times d]$,其中每一行对应一个输入词元。为了将来自编码器的键(keys)和值(values)与来自解码器前一层的查询(query)关联起来,我们将编码器输出 $\mathbf{H}_{enc}$ 分别与交叉注意力层的键权重 $\mathbf{W^K}$ 和值权重 $\mathbf{W^V}$ 相乘。 而查询则来自解码器前一层的输出 $\mathbf{H}_{dec[\ell-1]}$,并乘以交叉注意力层的查询权重 $\mathbf{W^Q}$:
$$ \begin{align*} \mathbf{Q} &= \mathbf{H}_{dec[\ell-1]} \mathbf{W^Q}; \\ \mathbf{K} &= \mathbf{H}_{enc} \mathbf{W^K}; \\ \mathbf{V} &= \mathbf{H}_{enc} \mathbf{W^V} \tag{12.11} \end{align*} $$$$ \text{CrossAttention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left( \frac{\mathbf{Q} \mathbf{K}^\top}{\sqrt{d_k}} \right) \mathbf{V} \tag{12.12} $$因此,交叉注意力使解码器能够关注源语言中每一个词在编码器最终表示中的投影。 每个解码器模块中的另一层注意力——即多头自注意力层——与第 8 章所见的因果注意力(从左到右)相同。 而编码器中的多头注意力则可以访问整个源语言文本,因此不使用掩码(unmasked)。
训练编码器-解码器模型时,我们采用与第 13 章训练 RNN 编码器-解码器相同的自监督学习方式。 网络接收源文本作为输入,并从分隔符(separator token)开始,以自回归方式训练,使用交叉熵损失来预测下一个词元。 回忆一下,语言建模中的交叉熵损失由模型赋予正确下一个词的概率决定。 因此,在时间步 $t$,交叉熵损失为模型对训练序列中下一个词 $w_{t+1}$ 所分配概率的负对数:
$$ L_{\text{CE}} (\hat{\mathbf{y}}_t , \mathbf{y}_t ) = -\log \hat{\mathbf{y}}_t [w_{t+1}] \tag{12.13} $$与 RNN 情况一样,我们在解码器中使用教师强制(teacher forcing)。 所谓教师强制,是指在解码的每一步,强制系统使用训练数据中的真实目标词元作为下一步的输入 $x_{t+1}$,而不是使用(可能出错的)解码器自身生成的输出 $\hat{y}_t$。