机器翻译(MT)的标准架构是编码器-解码器 Transformer,也称为序列到序列(sequence-to-sequence)模型——我们在第 13 章讨论 RNN 时将看到这一架构。 我们将在第 12.3 节详细介绍如何将该架构应用于 Transformer,但首先让我们先谈谈整体任务。
大多数机器翻译任务采用一个简化假设:每个句子可以独立翻译。因此,我们目前只考虑单个句子的翻译。 给定一个源语言(source language)句子,MT 的任务就是生成对应的目标语言(target language)句子。 例如,一个 MT 系统接收到如下英语句子:
The green witch arrived
并需将其翻译为西班牙语句子:
Llegó la bruja verde
机器翻译采用监督式机器学习:在训练阶段,系统会获得大量平行句对(parallel sentences)——即每个源语言句子都配有对应的目标语言译文,从中学习如何将源句映射为目标句。 在实际应用中,系统通常不会直接使用完整单词(如上例所示),而是将句子切分为一系列子词词元(subword tokens)——这些 token 可以是完整单词、子词片段,甚至是单个字符。 随后,系统被训练以最大化在给定源语言 token 序列 $x_1, \dots, x_n$ 的条件下,目标语言 token 序列 $y_1, \dots, y_m$ 的概率:
$$ P(y_1, \dots, y_m \mid x_1, \dots, x_n) \tag{12.7} $$编码器-解码器架构并不直接使用输入 token,而是由两个组件构成:编码器(encoder)和解码器(decoder)。 编码器接收输入序列 $x = [x_1, \dots, x_n]$,并生成一个中间上下文表示 $\mathbf{h}$。 在解码阶段,系统利用 $\mathbf{h}$,逐词生成输出序列 $y$:
$$ \begin{align*} \mathbf{h} = \text{encoder}(x) \tag{12.8} \\ y_{t+1} = \text{decoder}(\mathbf{h}, y_1, \dots, y_t) \quad \forall t \in [1, \dots, m] \tag{12.9} \end{align*} $$在接下来的两节中,我们将依次介绍子词词元化(subword tokenization)和如何获取用于训练的平行语料库,之后再深入讲解编码器-解码器架构的具体细节。
12.2.1 词元化
机器翻译系统使用一个预先固定好的词汇表。与直接使用空格分隔的单词不同,该词汇表是通过子词分词算法生成的,例如第 2 章简要介绍过的 BPE 算法。
通常,源语言和目标语言共享同一个词汇表,这使得系统可以轻松地将某些 token(如人名、专有名词)直接从源语言复制到目标语言。 采用跨语言共享的子词分词方式,还能自然地处理不同类型的语言:一类如英语或印地语,用空格分隔单词;另一类如汉语或泰语,则不使用空格分词。
我们通过在一个同时包含源语言和目标语言数据的语料库上运行子词分词算法来构建这个共享词汇表。
现代系统通常不再使用图 2.6 中那种简单的 BPE 算法,而是采用更强大的分词方法。
例如,一些系统(如 BERT)使用一种名为 WordPiece 的 BPE 变体。
与 BPE 选择“最频繁共现的 token 对进行合并”不同,WordPiece 选择的是能最大程度提升语言模型对整个分词结果概率的合并操作。
WordPiece 在每个 token 的开头使用一个特殊符号 _(下划线)表示该 token 是一个新词的起始。
以下是 Google 机器翻译系统(Wu et al., 2016)的一个分词示例:
原词: Jet makers feud over seat width with big orders at stake WordPiece: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
WordPiece 算法接收一个训练语料和一个目标词汇量 $V$,其流程如下:
- 初始化词汇表:以字符为基础(例如 Unicode 字符的一个子集),并将所有未覆盖的字符统一映射为一个特殊的
<UNK>(未知字符)token。 - 重复以下步骤,直到词汇表大小达到 $V$: (a) 使用当前的 WordPiece 集合,在训练语料上训练一个 n-gram 语言模型; (b) 考虑所有由当前词汇中两个相邻 WordPiece 拼接而成的新候选 token,选择那个最能提升训练语料整体语言模型概率的新 token 加入词汇表。
回想一下,使用 BPE 时我们需要指定“合并次数”;而 WordPiece 则直接指定最终词汇量,这一参数更直观、更易控制。 实践中,常见的 WordPiece 词汇量范围为 8K 到 32K。
如今更为广泛使用的分词算法是(略显模糊地)被称为 Unigram 算法(Kudo, 2018)的方法,有时也称作 SentencePiece 算法,并被 ALBERT(Lan et al., 2020)和 T5(Raffel et al., 2020)等系统采用。 (之所以常被称作 SentencePiece,是因为 Kudo 和 Richardson(2018b)开发了一个名为 SentencePiece 的开源库,它为多种分词算法提供了统一接口,而 Unigram 是其默认算法。因此,许多论文说“使用 SentencePiece 分词”,实际上指的是使用 Unigram 算法。)
与 BPE 或 WordPiece 自底向上合并 token 的方式不同,Unigram 算法采用自顶向下删减的策略:它首先构建一个极其庞大的初始词汇表,包含所有 Unicode 字符、所有常见字符序列(对于有空格的语言,还包括所有空格分隔的完整单词);然后迭代地移除部分 token,直到词汇量缩减至目标大小。 该算法较为复杂——涉及后缀树(suffix trees)以高效存储大量候选 token,以及使用 EM 算法(期望最大化算法)迭代估计每个 token 的概率。此处不展开细节,详见 Kudo(2018)及 Kudo & Richardson(2018b)。 简言之,其核心思想是:估算当前每个 token 的概率;用不同词元化方案对输入数据进行词元化;移除那些在高概率词元化中很少出现的 token;重复上述过程,直至词汇表缩小到所需规模。
为什么 Unigram 比 BPE 表现更好? BPE 存在两个主要问题:容易生成大量无实际语义的小片段(因为 BPE 只能逐字符合并,难以一次性形成有意义的词根或词干);倾向于将高频后缀(如 -ed)与其前邻词强行合并,破坏语义边界。 从 Bostrom 和 Durrett(2020)的以下例子可以看出,Unigram 通常能生成更具语义完整性的 token:
| 原文 | corrupted | Completely preposterous suggestions |
| BPE | cor rupted | Comple t ely prep ost erous suggest ions |
| Unigram | corrupt ed | Complete ly pre post er ous suggestion s |
12.2.2 训练数据的构建
机器翻译模型是在平行语料库(parallel corpus)上进行训练的,这种语料有时也称为双语文本(bitext),即同一内容以两种(或多种)语言呈现的文本。 目前已有大量平行语料可供使用。 其中一些来自政府机构:例如 Europarl 语料库(Koehn, 2005)是从欧洲议会会议记录中提取的,包含 21 种欧洲语言,每种语言约有 40 万至 200 万句; 联合国平行语料库(United Nations Parallel Corpus)则包含大约 1000 万句,涵盖联合国六种官方语言(阿拉伯语、中文、英语、法语、俄语、西班牙语)(Ziemski et al., 2016)。 其他平行语料则来源于电影和电视字幕,例如 OpenSubtitles 语料库(Lison and Tiedemann, 2016),或来自通用网络文本,例如从 CommonCrawl 中提取的 ParaCrawl 语料库,包含 23 种欧盟语言与英语之间的 2.23 亿个句子对(Bañón et al., 2020)。
句子对齐
标准的机器翻译训练语料以对齐的句子对形式提供。 但在为低资源语言或新领域构建新语料时,必须创建这些句子对齐。 图 12.4 展示了一个假设的句子对齐示例。
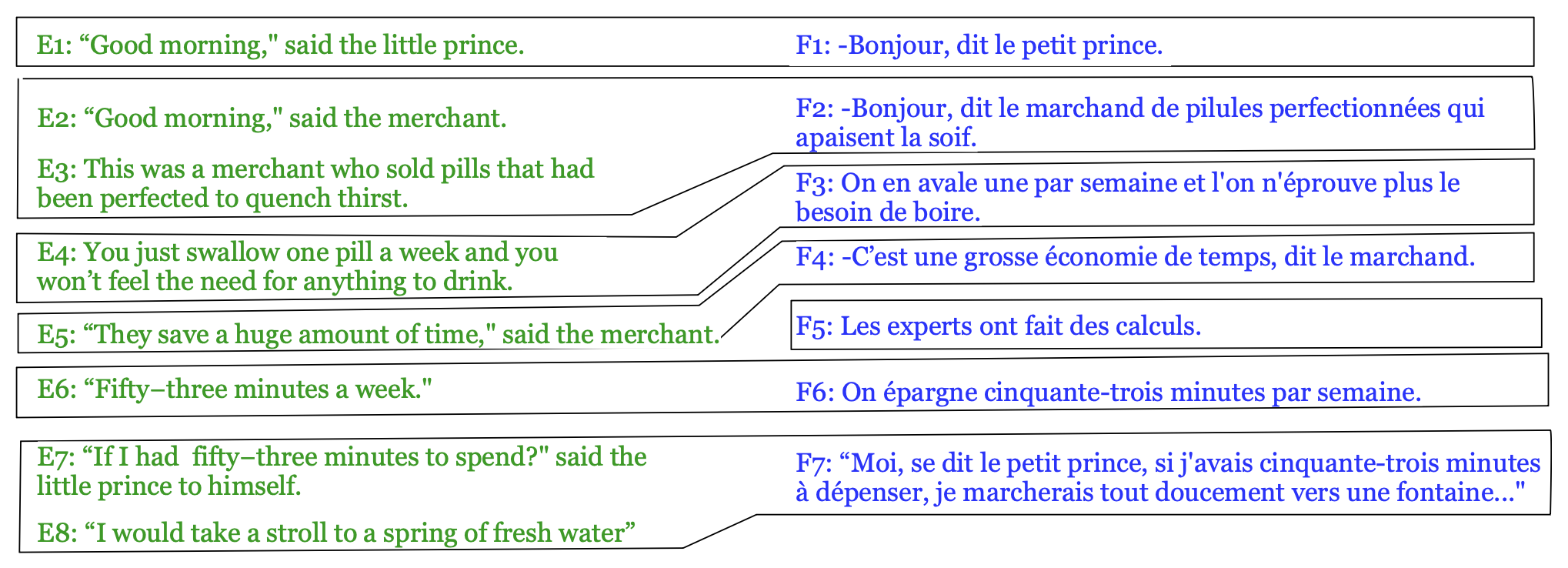
图 12.4 英语与法语句子之间的一个对齐示例,句子选自安托万·德·圣-埃克苏佩里的《小王子》及其假设译文。 句子对齐任务接收源语言句子序列 $e_1, \dots, e_n$ 和目标语言句子序列 $f_1, \dots, f_m$,并找出互为翻译的最小句子集合,包括一对一映射如 $(e_1,f_1)$、$(e_4,f_3)$、$(e_5,f_4)$、$(e_6,f_6)$,也包括多对一映射如 $(e_2/e_3,f_2)$、$(e_7/e_8,f_7)$,以及空对齐(如 $f_5$)。
给定两篇互为翻译的文档,我们通常需要两个步骤来生成句子对齐:
- 一个代价函数,它接收一段源语言句子和一段目标语言句子,并返回一个分数,用于衡量这两段内容互为翻译的可能性;
- 一个对齐算法,它利用这些分数在文档之间找到良好的对齐结果。
为了跨语言评估句子的相似度,我们需要使用多语言嵌入空间(multilingual embedding space),在该空间中,不同语言的句子被映射到同一个向量空间(Artetxe and Schwenk, 2019)。 在此类空间中,嵌入向量之间的余弦相似度自然构成一种评分函数(Schwenk, 2018)。 Thompson 和 Koehn(2019)提出了以下针对源文档片段 $x$ 与目标文档片段 $y$ 的代价函数:
$$ c(x,y) = \frac{(1 - \cos(x,y)) \cdot \text{nSents}(x) \cdot \text{nSents}(y)}{\sum_{s=1}^S (1 - \cos(x, y_s)) + \sum_{s=1}^S (1 - \cos(x_s, y))} \tag{12.10} $$其中 $\text{nSents}()$ 返回片段中的句子数量(这一设计使度量倾向于生成多个单句对齐,而非将非常大的片段整体对齐)。分母用于对相似度进行归一化,其中 $x_1, \dots, x_S$ 和 $y_1, \dots, y_S$ 是从各自文档中随机采样的句子。
通常采用动态规划作为对齐算法(Gale and Church, 1993),这是第 2 章介绍的最小编辑距离算法的一个简单扩展。
最后,去除噪声句子有助于清洗语料。 这可以包括使用人工编写的规则来剔除低精度的句子对(例如删除过长、过短、包含不同 URL 的句子,甚至那些过于相似、可能为复制而非翻译的句子对),也可以根据多语言嵌入的余弦相似度对句子对进行排序,并丢弃得分较低的对。