在此,我们介绍一种利用大语言模型(LLM)回答知识型问题的重要范式:首先从网络或其他大型文档集合中检索出支持性的文本片段,然后基于这些文档生成答案。 这种基于检索结果进行生成的方法被称为检索增强生成(Retrieval-Augmented Generation, RAG),其两个组成部分出于历史原因常被分别称为检索器(retriever)和阅读器(reader)(Chen 等,2017a)。 图 11.9 概述了这一标准的问答模型。
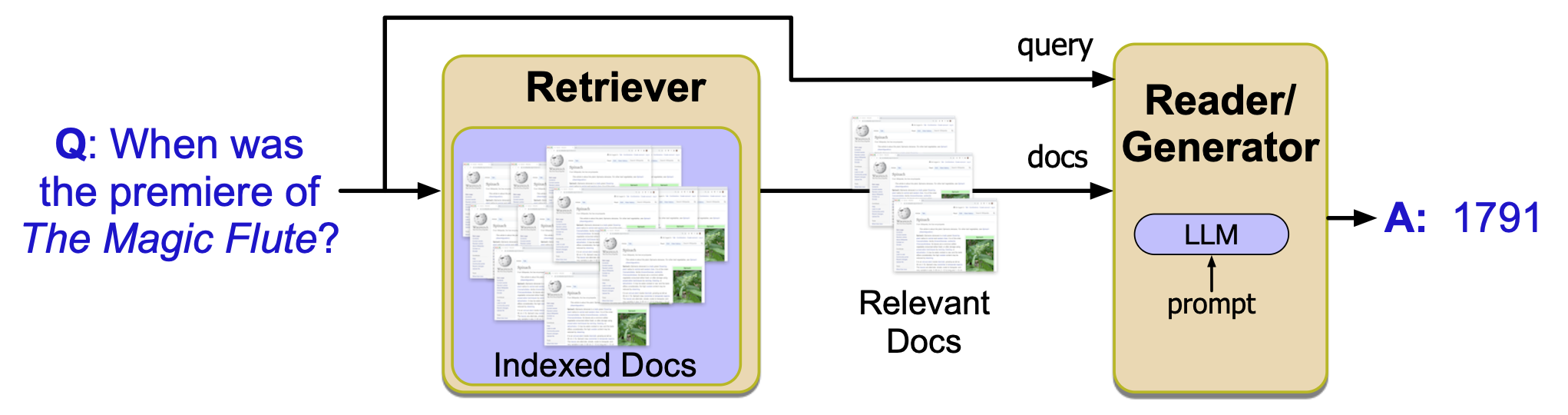
图 11.9 基于检索的问答包含两个阶段:检索阶段从文档集合中返回相关文档;阅读阶段中,大语言模型以这些文档作为提示(prompt)生成答案。
如图 11.9 所示的“检索-阅读”两阶段模型中,在第一阶段(检索阶段),我们从一个文本集合中检索出相关段落,例如使用上一节介绍的稠密检索器。 在第二阶段(阅读器阶段),我们通过检索增强生成(RAG)来生成答案。 将一个大规模预训练语言模型作为基础,把检索到的段落及其他文本作为提示输入,并以自回归方式逐个生成答案词元。
11.3.1 检索增强生成(RAG)
标准的阅读器算法是:在检索到的段落条件下,由大语言模型生成答案。 这种方法即为检索增强生成(Retrieval-Augmented Generation, RAG)。
回顾一下,在简单的条件生成中,我们可以将问答任务转化为词预测问题:给语言模型一个提问,并附加一个如 A: 的标记,暗示接下来应生成答案:
Q: 谁写了《物种起源》这本书? A:
然后,模型基于该文本进行自回归生成。
更形式化地说,普通的自回归语言模型通过前面的词元计算整个字符串的概率:
$$ p(x_1, \dots, x_n) = \prod_{i=1}^n p(x_i \mid x_{< i}) $$而用于问答的简单条件生成则将提示(如 Q:)、查询 $q$ 和 A: 拼接在一起:
使用大语言模型的优势在于,其参数中编码了预训练时所学得的海量知识。 然而,正如本章开头所述,尽管这种简单的提示生成对许多简单的事实型问题效果不错,但它并非通用的问答解决方案,原因包括:容易产生幻觉;无法向用户提供支持答案的文本证据;无法回答涉及专有数据的问题。
检索增强生成的核心思想正是为了解决这些问题:将检索到的段落作为前缀的一部分加入提示中,通常还会附加一段引导语,例如 “请根据以下文本回答问题:”。 假设我们有一个查询 $q$,并记基于它检索到的段落集合为 $R(q)$,那么提示可能如下所示:
RAG 提示示例
检索到的段落 1
检索到的段落 2
…
检索到的段落 n
请根据以上文本回答以下问题:Q: 谁写了《物种起源》这本书? A:
更形式化地,生成概率可表示为:
$$ p(x_1, \dots, x_n) = \prod_{i=1}^n p\big(x_i \mid R(q);\, \text{prompt};\, [Q:];\, q;\, [A:];\, x_{< i}\big) $$与基于片段抽取的阅读器类似,成功应用 RAG 进行问答高度依赖一个高效的检索器。实践中常采用两阶段检索架构:先粗排再重排序(rerank)。
对于某些复杂问题,可能还需要多跳(multi-hop)架构——即先用原始查询检索一批文档,再将这些文档内容附加到原查询上,进行第二轮检索。
此外,还需仔细设计提示工程细节,例如是否用 [SEP] 等特殊标记分隔不同段落。
当系统结合私有数据与公有数据,并调用外部托管的大语言模型时,还可能引发隐私问题,需要专门处理(Arora 等,2023)。
当前该领域的大量研究也聚焦于如*更紧密地耦合检索与生成两个阶段。