传统的 tf-idf 或 BM25 信息检索算法长期以来被认为存在一个概念性缺陷:它们仅在查询与文档之间存在完全相同的词语重叠时才有效。 换句话说,用户在提出查询(或问题)时,必须准确猜中答案撰写者所使用的词汇,这一问题被称为词汇不匹配问题(vocabulary mismatch problem)(Furnas 等,1987)。
解决该问题的方法是采用能够处理同义关系(synonymy)的模型:不再使用(稀疏的)词频向量,而是使用(稠密的)嵌入向量(embeddings)。 这一思想早在上世纪就已提出,称为潜在语义索引(Latent Semantic Indexing, LSI)(Deerwester 等,1990),而在现代则通过 BERT 等编码器实现。
目前最强大的方法是将查询和文档同时输入同一个编码器,让 Transformer 的自注意力机制同时看到查询和文档中的所有词元(tokens),从而构建出对两者语义都敏感的联合表示。
随后,可以在 [CLS] 词元之上添加一个线性层,用于预测该查询-文档对的相关性得分:
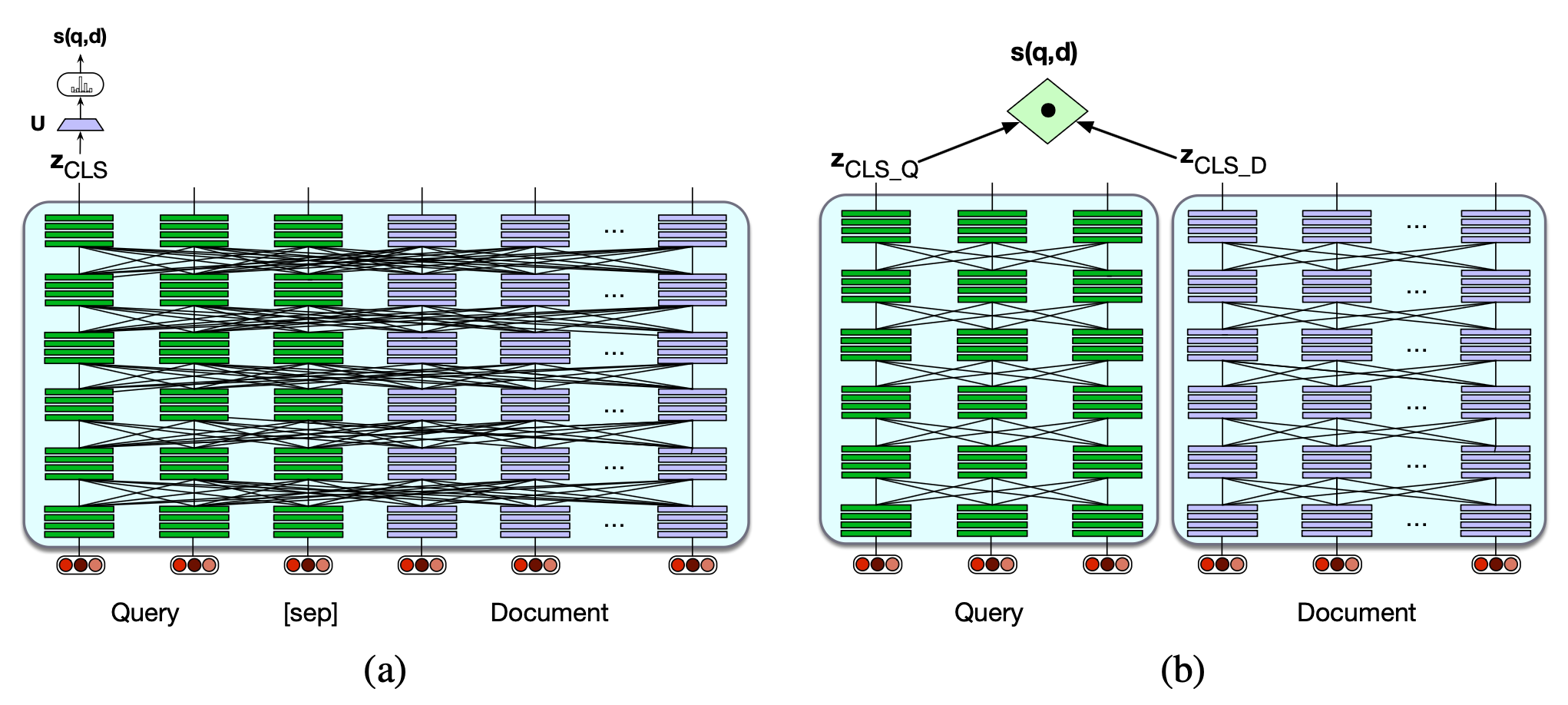
图 11.7 两种稠密检索方法的示意图(图中连线示意自注意力机制的作用范围):
(a) 使用单一编码器联合编码查询与文档,并在 [CLS] 词元上通过线性层微调生成相关性得分。此方法计算开销过大,通常仅用于重排序(re-scoring)阶段;
(b) 使用独立的查询编码器和文档编码器,通过两者 [CLS] 输出向量的点积作为得分。此方法计算高效,但精度略低。
该架构如图 11.7a 所示。
通常,检索步骤不会在整个文档上进行,而是将文档切分为更小的段落(passages),例如长度为 100 个词元的非重叠固定片段,然后对这些段落而非完整文档进行编码和检索。
由于 BERT 的输入窗口限制为 512 个词元,因此需要确保查询和文档能共同容纳其中。例如,可将查询截断至最多 64 个词元,并在必要时截断文档,使得查询、文档、[CLS] 和 [SEP] 总共不超过 512 个词元。
随后,整个 BERT 模型连同线性层 $\mathbf{U}$ 可以通过一个包含相关与不相关段落的微调数据集,针对相关性判断任务进行微调。
然而,图 11.7a 所示的完整 BERT 架构存在计算开销过大的问题。 使用该架构时,每次收到新查询,都必须将整个文档集合中的每一篇文档与该查询一起送入 BERT 编码器进行联合编码! 这种巨大的资源消耗在实际应用中是不可行的。
在计算效率的另一端,是一种更为高效的架构——双编码器(bi-encoder)。
在此架构中,我们只需对集合中的文档编码一次,方式是使用两个独立的编码器模型,一个用于编码查询,另一个用于编码文档。
我们可以预先对文档集合中的所有文档进行一次编码,并将得到的文档向量存储起来。
当新查询到来时,只需对该查询进行一次编码,然后通过计算查询向量与所有预计算文档向量之间的点积,即可快速得到每个候选文档的得分(见图 11.7b)。
例如,若使用 BERT,则可分别用两个编码器 $\text{BERT}_Q$ 和 $\text{BERT}_D$ 对查询和文档进行编码,并取各自输出的 [CLS] 词元作为其向量表示(Karpukhin 等,2020):
双编码器(bi-encoder)相比完整的查询/文档联合编码器,计算成本要低得多,但精度也较低,因为它无法充分利用查询中所有词元与文档中所有词元之间可能存在的丰富语义交互来判断相关性。
在完整编码器与双编码器之间,还存在许多折中方案。 一种常见的中间策略是:先用低成本方法(如 BM25),从中选出排名靠前的 $N$ 篇文档,再对这 $N$ 篇文档使用高成本的完整 BERT 评分模型进行重排序(re-ranking)。
另一种重要的中间方法是 ColBERT(Khattab 和 Zaharia, 2020;Khattab 等, 2021),如图 11.8 所示。 该方法虽然也分别对查询和文档进行编码,但并不将整个查询或文档压缩成单个向量,而是为其中每个词元生成独立的上下文表示。 这些基于 BERT 的文档词元表示可以预先存储以提升效率。 ColBERT 中查询 $q$ 与文档 $d$ 的相关性得分,通过一种称为最大相似度求和(MaxSim)的操作计算。 对于查询中的每个词元,ColBERT 在文档的所有词元中找到与其上下文最相似的一个,然后将所有这些最大相似度值相加。 一篇相关文档,其内部应包含多个与查询词元高度语义匹配的词元。
$$ \text{score}(q,d) = \sum_{i=1}^{N} \max_{j=1}^{m} \left( \mathbf{E}_{q_i} \cdot \mathbf{E}_{d_j} \right) \tag{11.19} $$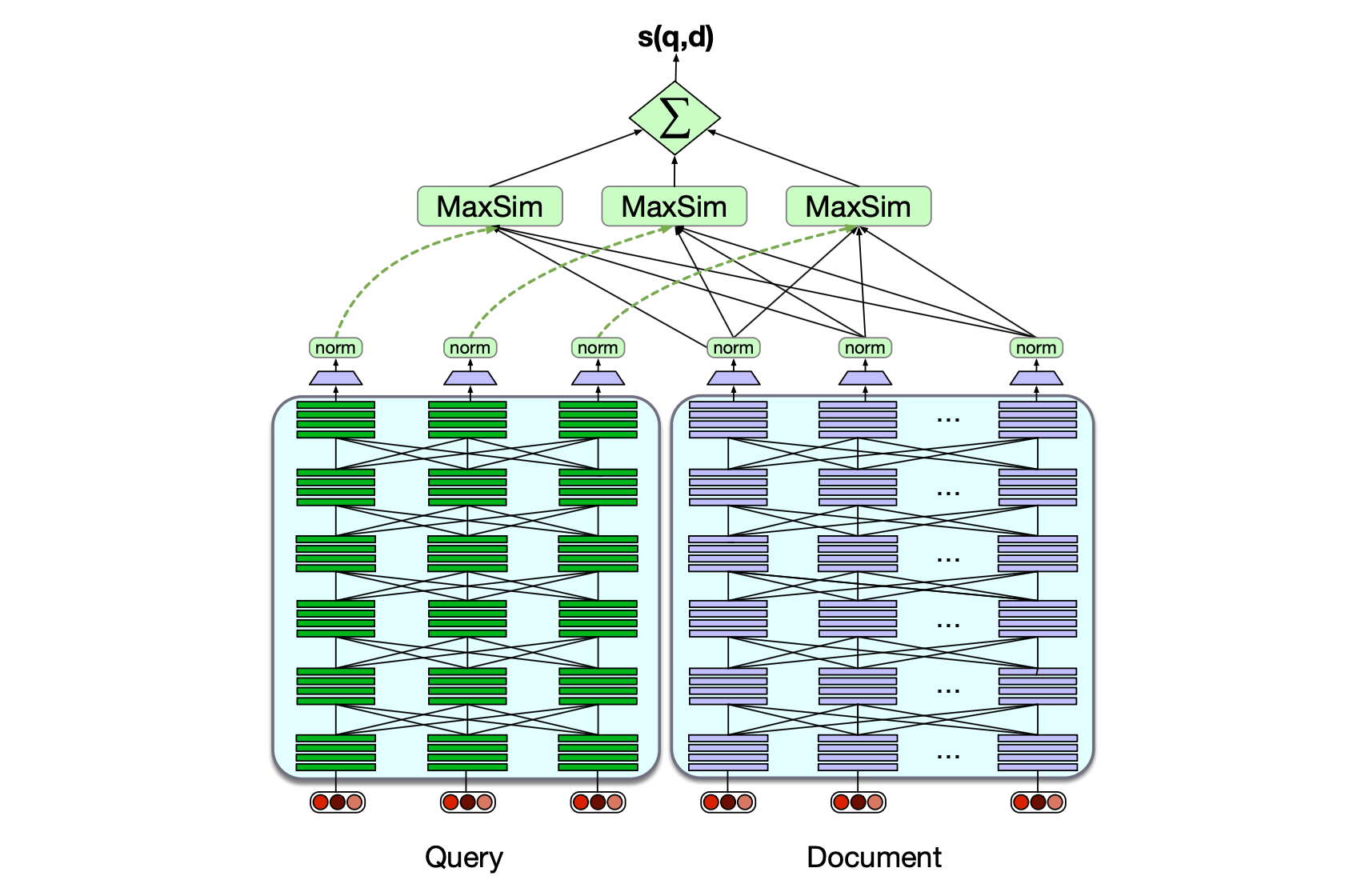
图 11.8 ColBERT 算法在推理阶段的示意图。
查询和文档首先分别通过独立的 BERT 编码器。
查询与文档之间的相似度通过对其词元上下文表示进行“软对齐”并求和得到。
模型采用端到端训练。
(图中省略了一些细节;例如查询前会添加 [CLS] 和 [Q:] 标记,文档前添加 [CLS] 和 [D:] 标记。图改编自 Khattab 和 Zaharia, 2020。)
更形式化地描述:查询 $q$ 被词元化为 $[q_1, \dots, q_n]$,并在开头添加 [CLS] 和一个特殊标记 [Q],随后截断至 $N = 32$ 个词元(若不足则用 [MASK] 填充),再送入 BERT 编码器,得到输出向量序列 $\mathbf{q} = [\mathbf{q}_1, \dots, \mathbf{q}_N]$。
文档段落 $d$(词元序列为 $[d_1, \dots, d_m]$)也类似处理,添加 [CLS] 和特殊标记 [D]。
接着,在 $\mathbf{q}$ 和 $\mathbf{d}$ 上各加一个线性层,以控制输出维度(便于存储),并将所有向量归一化为单位长度,最终得到查询向量序列 $\mathbf{E}_q$(长度 $N$)和文档向量序列 $\mathbf{E}_d$(长度 $m$)。ColBERT 的打分机制定义为:
尽管 ColBERT 的交互机制(即 MaxSim 操作)本身不含可学习参数,但整个架构仍需端到端训练,以微调 BERT 编码器、训练顶部的线性层,并从头学习特殊的 [Q] 和 [D] 嵌入表示。
训练时使用三元组数据 $\langle q, d^+, d^- \rangle$(包含查询 $q$、正样本文档 $d^+$ 和负样本文档 $d^-$),利用公式 (11.19) 为每个文档计算得分,并通过交叉熵损失优化模型参数。
所有这类监督学习算法(如 ColBERT,或用于重排序的完整交互式 BERT 模型)都需要训练数据:即包含相关(正例)和不相关(负例)段落或文档的查询-文档对。 获取标注数据有多种半监督方式:某些数据集(如 MS MARCO Ranking,见第 11.4 节)已提供人工标注的正例; 负例通常可从现有 IR 系统返回的 top-1000 结果中随机采样; 若数据集中缺乏正例标注,可采用 相关性引导监督(relevance-guided supervision)等迭代方法(Khattab 等, 2021)。该方法利用一个事实:许多数据集包含简短的答案字符串。 具体做法是:先用现有 IR 系统检索结果,将包含答案字符串的前几篇视为正例,不包含的前几篇视为负例;用这些自动构建的样本训练一个新的检索器,再重复此过程进行迭代优化。
效率是一个关键问题,因为系统需要对所有可能的文档计算其与查询的相似度。 对于稀疏的词频向量,倒排索引能非常高效地完成这一任务。 而对于稠密向量算法,寻找与查询向量点积最大的文档向量集合,本质上是一个最近邻搜索(nearest neighbor search)问题。 因此,现代系统普遍采用近似最近邻(Approximate Nearest Neighbor, ANN)搜索算法,例如 Faiss(Johnson 等, 2017)。