信息检索(Information Retrieval,简称 IR)是研究如何根据用户信息需求检索各类媒体内容的领域。 由此构建的 IR 系统通常被称为搜索引擎。 本节的目标是提供足够的 IR 概述,以便理解其在问答任务中的应用。 对信息检索本身更感兴趣的读者可参阅本章末尾的“历史注记”部分以及 Manning 等人(2008)等教科书。
我们所讨论的 IR 任务称为即席检索(ad hoc retrieval):用户向检索系统提交一个查询(query),系统随后从某个文档集合(collection)中返回一个有序的文档(documents)列表。 此处的“文档”指系统所索引和检索的任意文本单位,例如网页、学术论文、新闻文章,甚至更短的片段(如段落)。 “集合”则指用于满足用户请求的一组文档。 “词条”(term)通常指集合中的一个词,但也可能包括短语。 最后,查询(query)表示用户以一组词条形式表达的信息需求。 即席检索引擎的高层架构如图 11.1 所示。
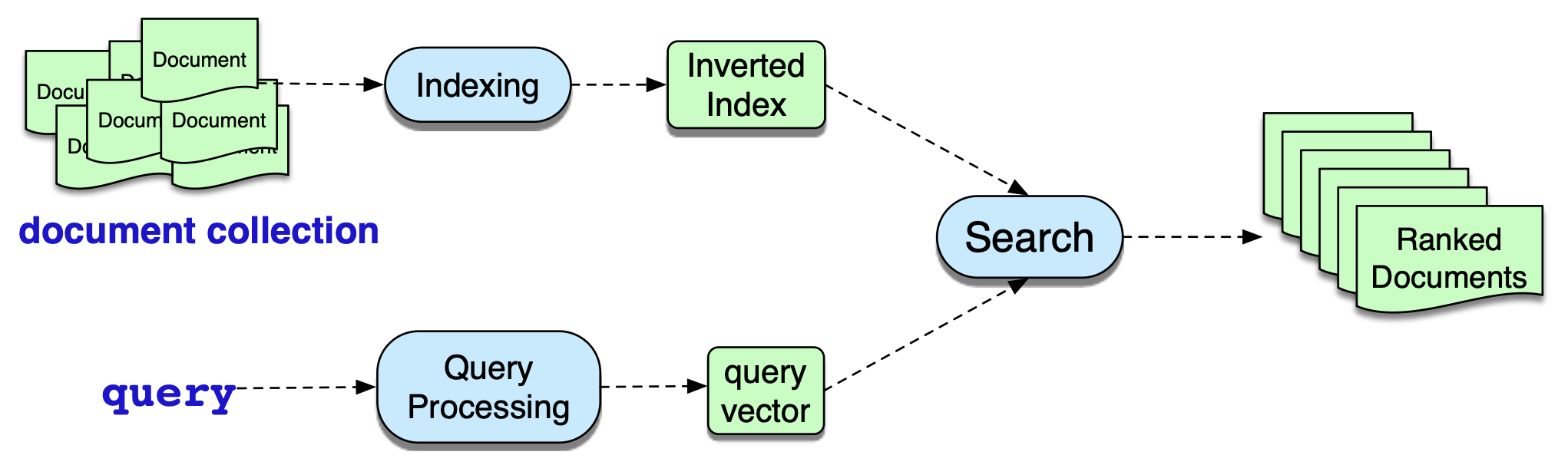
图 11.1 即席 IR 系统的架构。
基本的 IR 架构采用我们在第 5 章介绍的向量空间模型:将查询和文档映射为基于一元词频(unigram word counts)的向量,并利用向量之间的余弦相似度对候选文档进行排序(Salton, 1971)。 因此,这属于附录 K 中介绍的词袋模型(bag-of-words model)的一个实例,因为其中词语的处理不考虑其在文本中的位置。
11.1.1 词条加权与文档评分
我们来看文档与查询之间匹配得分的具体计算方式。
在信息检索中,我们不直接使用原始词频,而是为文档中的每个词计算一个词条权重(term weight)。 常用的词条加权方案有两种:第5章介绍过的 tf-idf 加权,以及一种稍强一些的变体BM25。
为方便读者,此处重新介绍 tf-idf,避免回看第5章。 Tf-idf(这里的“-”是连字符,不是减号)是两个因子的乘积:词频(term frequency, tf)和逆文档频率(inverse document frequency, idf)。
词频反映一个词在文档中出现的频繁程度;在文档中出现次数越多的词,越可能体现该文档的内容。 通常我们使用词频的以10为底的对数($\log_{10}$),而非原始计数。 其理由是:一个词在文档中出现100次,并不意味着它对该文档语义的相关性就是出现1次时的100倍。 此外,对于计数为 0 的情况需特殊处理,因为我们无法对 0 取对数。1
$$ \begin{align*} tf_{t,d} = \begin{cases} 1 + \log_{10} \text{count}(t,d) & \text{if } \text{count}(t,d) > 0 \\ 0 & \text{otherwise} \end{cases} \tag{11.4} \end{align*} $$若采用对数加权,那么在文档中出现 0 次的词条 tf = 0;出现1次时,tf = 1 + log₁₀(1) = 1 + 0 = 1;出现10次时,tf = 1 + log₁₀(10) = 2;出现100次时,tf = 1 + log₁₀(100) = 3;出现1000次时,tf = 4,依此类推。
词条 $t$ 的文档频率(document frequency, $df_t$)是指包含该词条的文档数量。 仅在少数文档中出现的词条,有助于将这些文档与其他文档区分开;而几乎在所有文档中都出现的词条则区分能力较弱。 逆文档频率(inverse document frequency, idf)词条权重(Sparck Jones, 1972)定义如下:
$$ idf_t = \log_{10}\frac{N}{df_t} \tag{11.5} $$其中,$N$ 是文档集合中的总文档数,$df_t$ 是包含词条 $t$ 的文档数量。 词条出现的文档越少,该权重越高;对于在所有文档中都出现的词条,其最低权重为 0。
下表列出莎士比亚戏剧语料库中部分词语的 idf 值,范围从仅在一部剧中出现、极具区分性的词(如 Romeo),到在几部剧中出现的词(如 salad 或 Falstaff),再到非常常见的词(如 fool),乃至因在全部 37 部剧中均出现而完全丧失区分能力的词(如 good 或 sweet)。2
| 词语 | df | idf |
|---|---|---|
| Romeo | 1 | 1.57 |
| salad | 2 | 1.27 |
| Falstaff | 4 | 0.967 |
| forest | 12 | 0.489 |
| battle | 21 | 0.246 |
| wit | 34 | 0.037 |
| fool | 36 | 0.012 |
| good | 37 | 0 |
| sweet | 37 | 0 |
文档 $d$ 中词条 $t$ 的 tf-idf 值即为词频 $tf_{t,d}$ 与逆文档频率 $idf_t$ 的乘积:
$$ tf\text{-}idf(t,d) = tf_{t,d} \cdot idf_t \tag{11.6} $$11.1.2 文档评分
我们计算文档向量 $\mathbf{d}$ 与查询向量 $\mathbf{q}$ 之间的余弦值,得到文档 $d$ 的评分:
$$ \text{score}(q,d) = \cos(\mathbf{q},\mathbf{d}) = \frac{\mathbf{q} \cdot \mathbf{d}}{|\mathbf{q}||\mathbf{d}|} \tag{11.7} $$另一种理解余弦计算的方式是单位向量的点积。 我们首先将查询向量和文档向量分别除以其长度,归一化为单位向量,然后计算它们的点积:
$$ \text{score}(q,d) = \cos(\mathbf{q},\mathbf{d}) = \frac{\mathbf{q}}{|\mathbf{q}|} \cdot \frac{\mathbf{d}}{|\mathbf{d}|} \tag{11.8} $$我们可以将公式 (11.8) 展开,代入 tf-idf 值,并将点积显式写成各项乘积之和的形式:
$$ \text{score}(q,d) = \sum_{t \in q} \frac{\text{tf-idf}(t,q)}{\sqrt{\sum_{q_i \in q} \text{tf-idf}^2(q_i,q)}} \cdot \frac{\text{tf-idf}(t,d)}{\sqrt{\sum_{d_i \in d} \text{tf-idf}^2(d_i,d)}} \tag{11.9} $$现在,我们使用公式 (11.9) 演示一个简短查询示例。这个示例包含4个微型文档(nano documents),我们计算 tf-idf 值并观察文档的排序结果。 假设以下查询和文档中的所有单词均已转为小写,且标点符号已被移除:
Query: sweet love
Doc 1: Sweet sweet nurse! Love?
Doc 2: Sweet sorrow
Doc 3: How sweet is love?
Doc 4: Nurse!
图 11.2 展示了查询与文档 1、以及查询与文档 2 之间 tf-idf 余弦值的计算过程。 余弦值即 tf-idf 向量的归一化点积。因此,在归一化时,我们需要利用公式 (11.4)、(11.5)、(11.6) 和 (11.9),分别计算查询、文档 1 和文档 2 的向量长度 $|\mathbf{q}|$、$|\mathbf{d}_1|$ 和 $|\mathbf{d}_2|$。(文档 3 和 4 的计算同样需要,但留作读者练习。) 两个向量的点积是对每个维度上对应 tf-idf 值乘积的求和。 只有当查询和文档在某个维度(即某个词条)上均具有非零值时,该维度的乘积才非零。在本例中,查询中仅有 sweet 和 love 两个词条的值非零,因此点积仅包含这两个词条对应分量的乘积之和。

图 11.2 使用公式 (11.4)、(11.5)、(11.6) 和 (11.9) 计算查询与微型文档 1(余弦值 0.747)和文档 2(余弦值 0.0779)之间的 tf-idf 余弦得分。
文档 1 与查询的余弦相似度(0.747)高于文档 2 与查询的余弦相似度(0.0779),因此 tf-idf 余弦模型会将文档 1 排在文档 2 之前。 这一排序符合向量空间模型的直观预期:文档 1 同时包含两个查询词(其中 sweet 出现两次),而文档 2 缺少其中一个词(love)。 文档 3 和 4 的计算留作读者练习。
在实践中,公式 (11.9) 有许多变体和近似形式。 例如,我们可能会选择简化处理过程,通过移除某些项来实现。 为说明这一点,我们首先将公式 (11.9) 中的 tf-idf 显式展开,代入公式 (11.6) 中的 tf 和 idf 项:
$$ \text{score}(q,d) = \sum_{t \in q} \frac{tf_{t,q} \cdot idf_t}{\sqrt{\sum_{q_i \in q} \text{tf-idf}^2(q_i,q)}} \cdot \frac{tf_{t,d} \cdot idf_t}{\sqrt{\sum_{d_i \in d} \text{tf-idf}^2(d_i,d)}} \tag{11.10} $$在一种常见的 tf-idf 余弦变体中,我们会省略文档侧的 idf 项。 由于查询侧已经计算了相同的 idf 项,去掉文档中的第二个 idf 副本有时反而能带来更好的检索性能:
$$ \text{score}(q,d) = \sum_{t \in q} \frac{tf_{t,q} \cdot idf_t}{\sqrt{\sum_{q_i \in q} \text{tf-idf}^2(q_i,q)}} \cdot \frac{tf_{t,d}}{\sqrt{\sum_{d_i \in d} \text{tf-idf}^2(d_i,d)}} \tag{11.11} $$tf-idf 还有其他多种变体,会省略不同的项。
tf-idf 家族中一个稍复杂的变体是 BM25 加权方案(有时称为 Okapi BM25,因其最初在 Okapi 信息检索系统中提出(Robertson 等,1995))。 BM25 引入了两个参数:$k$ 用于调节词频(tf)与 IDF 之间平衡的调节因子;$b$ 控制文档长度归一化重要程度的参数。 给定查询 $q$,文档 $d$ 的 BM25 得分为:
$$ \sum_{t \in q} \overbrace{\log\left(\frac{N}{df_t}\right)}^{\text{IDF}} \cdot \overbrace{\frac{tf_{t,d}}{k\left(1 - b + b\left(\frac{|d|}{|d_{\text{avg}}|}\right)\right) + tf_{t,d}}}^{\text{加权 tf}} \tag{11.12} $$其中,$|d_{\text{avg}}|$ 表示平均文档长度。 当 $k = 0$ 时,BM25 不使用词频,仅对查询中的词条进行二值化匹配(并结合 IDF); 当 $k$ 较大时,BM25 趋近于直接使用原始词频(加上 IDF); 参数 $b$ 的取值范围为 0 到 1:$b = 1$ 表示完全按文档长度进行归一化,$b = 0$ 表示不进行长度归一化。 Manning 等人(2008)建议的合理取值范围为 $k \in [1.2, 2]$,$b = 0.75$。 Kamphuis 等人(2020)对 BM25 的众多细微变体进行了有用综述。
停用词(Stop words)
过去,通常会在表示查询和文档之前,先移除其中的高频词。 这类被移除的高频词列表被称为停用词表(stop list)。 其理由是:高频词(通常是功能词,如 the、a、to)语义信息较少,对检索帮助不大,同时还能缩小下文将介绍的倒排索引文件的体积。 然而,使用停用词表的缺点是:难以搜索包含停用词的短语。 例如,常见的停用词表会把短语 to be or not to be 简化为 not。 在现代信息检索系统中,停用词表的使用已大大减少,部分原因是系统效率的提升,部分原因是 IDF 加权机制本身已能有效抑制那些在所有文档中都出现的功能词(为其赋予接近零的权重)。 尽管如此,在某些自然语言处理任务中,移除停用词偶尔仍有用处,因此仍值得关注。
11.1.3 倒排索引
为了计算得分,我们需要高效地找出包含查询中词语的文档。 (任何不包含任一查询词的文档得分均为 0,可直接忽略。) 因此,信息检索中的基本搜索问题就是:找出集合 $C$ 中所有包含查询词 $q \in Q$ 的文档 $d$。
解决此任务所用的数据结构是倒排索引(inverted index),它不仅使此类搜索变得高效,还能方便地存储有用的信息,例如每个词条的文档频率(document frequency)以及其在各文档中的出现次数。
给定一个查询词,倒排索引会返回包含该词的文档列表。
它由两部分组成:词典(dictionary)和倒排记录表(postings)。
词典是一个词条列表(设计为可高效访问),其中每个词条指向其对应的倒排记录列表(postings list)。
倒排记录列表是与该词条关联的文档 ID 列表,还可包含额外信息,如词频(term frequency),甚至词条在文档中的精确位置。
词典本身也可存储每个词条的文档频率。
例如,针对前述 4 个示例文档,一个简单的倒排索引可能如下所示:每个词条后的大括号 {} 中标注其文档频率,箭头指向的倒排记录列表用方括号 [] 表示,其中包含文档 ID 及该词条在对应文档中的出现次数:
how {1} → 3 [1]
is {1} → 3 [1]
love {2} → 1 [1] → 3 [1]
nurse {2} → 1 [1] → 4 [1]
sorry {1} → 2 [1]
sweet {3} → 1 [2] → 2 [1] → 3 [1]
给定查询中的词条列表,我们可以非常高效地获取所有候选文档的列表,并同时获得计算所需 tf-idf 得分的必要信息。
倒排索引并非唯一选择。 在问答任务中,若目标是从维基百科页面中检索与用户查询匹配的页面,Chen 等人(2017a)指出,基于 bigrams 的索引效果优于 unigrams,并采用高效的哈希算法(而非倒排索引)来实现高效搜索。
11.1.4 信息检索系统的评估
我们使用此前介绍过的准确率(precision)和召回率(recall)指标来衡量排序检索系统的性能。 这里假设信息检索系统返回的每篇文档要么相关(relevant),要么不相关(not relevant)。 准确率是指返回文档中相关文档所占的比例; 召回率是指所有相关文档中被成功返回的比例。 更形式化地,假设系统针对某条信息请求返回了 $T$ 篇按序排列的文档,其中子集 $R$ 为相关文档,互不相交的子集 $N$ 为其余不相关文档,而整个文档集合中与此请求相关的文档总数为 $U$。那么准确率和召回率定义如下:
$$ \begin{align*} \text{Precision} &= \frac{|R|}{|T|} \\ \text{Recall} &= \frac{|R|}{|U|} \tag{11.13} \end{align*} $$然而,这些指标不足以充分衡量一个对结果进行排序的系统的性能。 当比较两个排序检索系统时,我们需要一种更精细的度量方式:优先选择那些将相关文档排得更靠前的系统。 因此,我们必须对准确率和召回率加以改进,以反映系统在排序中将相关文档置于高位的能力。
| 排名 | 判定 | $\text{Precision}_{\text{Rank}}$ | $\text{Recall}_{\text{Rank}}$ |
|---|---|---|---|
| 1 | R | 1.0 | 0.11 |
| 2 | N | 0.50 | 0.11 |
| 3 | R | 0.66 | 0.22 |
| 4 | N | 0.50 | 0.22 |
| 5 | R | 0.60 | 0.33 |
| 6 | R | 0.66 | 0.44 |
| 7 | N | 0.57 | 0.44 |
| 8 | R | 0.63 | 0.55 |
| 9 | N | 0.55 | 0.55 |
| 10 | N | 0.50 | 0.55 |
| 11 | R | 0.55 | 0.66 |
| 12 | N | 0.50 | 0.66 |
| 13 | N | 0.46 | 0.66 |
| 14 | N | 0.43 | 0.66 |
| 15 | R | 0.47 | 0.77 |
| 16 | N | 0.44 | 0.77 |
| 17 | N | 0.44 | 0.77 |
| 18 | R | 0.44 | 0.88 |
| 19 | N | 0.42 | 0.88 |
| 20 | N | 0.40 | 0.88 |
| 21 | N | 0.38 | 0.88 |
| 22 | N | 0.36 | 0.88 |
| 23 | N | 0.35 | 0.88 |
| 24 | N | 0.33 | 0.88 |
| 25 | R | 0.36 | 1.0 |
图 11.3 在遍历一组排序文档时逐位计算的排名相关准确率与召回率(假设整个集合中共有 9 篇相关文档)。
我们来看一个例子。 假设图 11.3 中的表格给出了针对某一查询,在依次向下遍历系统返回的排序文档列表时,于每个排名位置处计算得到的准确率和召回率。 其中,准确率表示截至当前排名为止,已返回文档中相关文档的比例;召回率表示截至当前排名为止,已找到的相关文档占全部相关文档的比例。 本例中的召回率基于这样一个前提:该查询在整个文档集合中共有 9 篇相关文档。
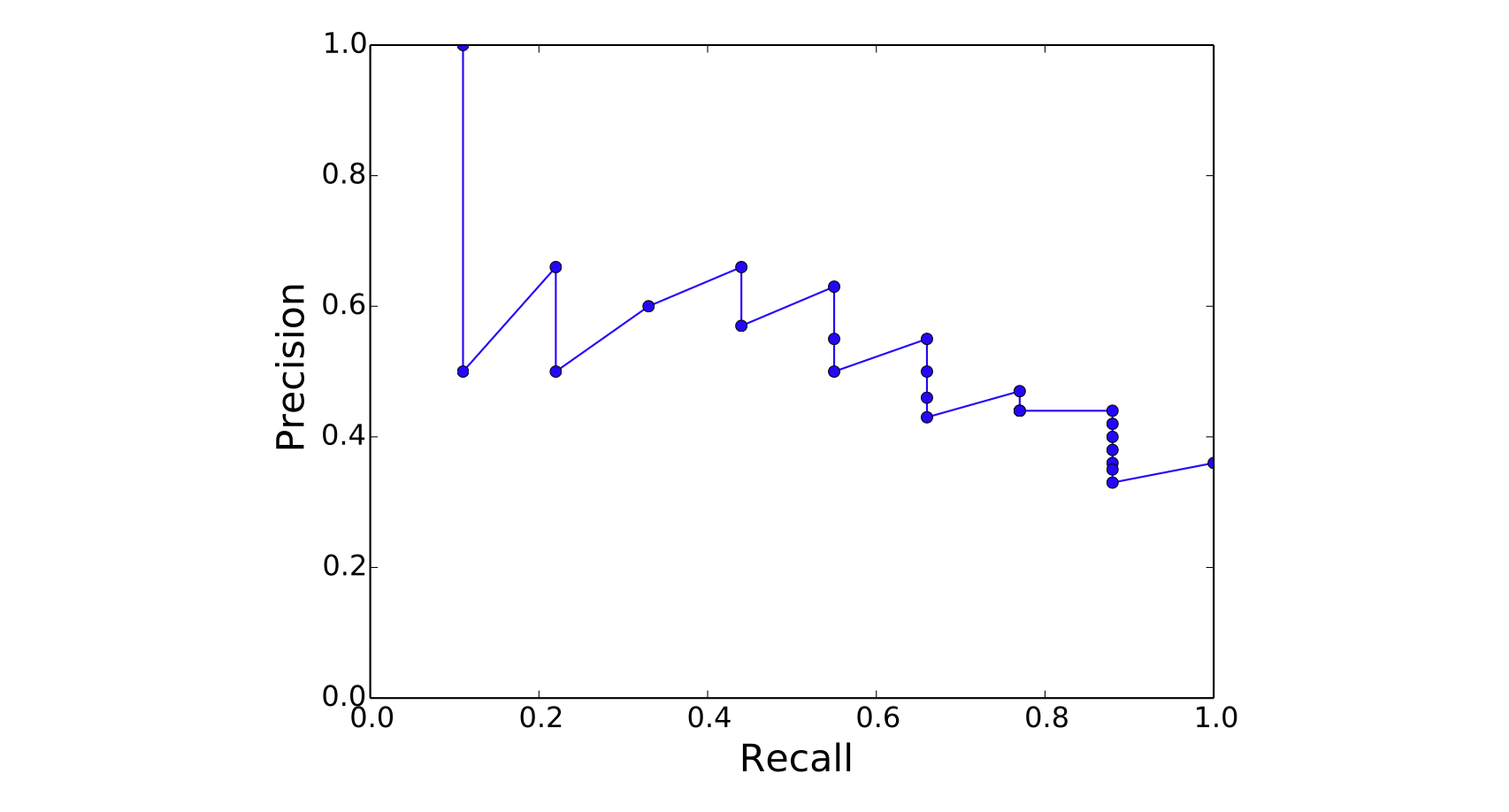
图 11.4 基于表 11.3 数据绘制的准确率-召回率曲线。
请注意,召回率是非递减的:每当遇到一篇相关文档时,召回率就会上升;而遇到不相关文档时,召回率保持不变。 相比之下,准确则会上下波动:遇到相关文档时上升,遇到不相关文档时下降。
可视化准确率与召回率最常用的方式是绘制准确率-召回率曲线(precision-recall curve),即以召回率为横轴、准确率为纵轴作图,如图 11.4 所示,该图基于表 11.3 的数据。
图 11.4 展示的是单个查询的结果。 但在实际评估中,我们需要将所有查询的结果综合起来,并以一种便于系统间比较的方式进行汇总。 一种常用方法是在 11 个固定的召回率水平(从 0 到 1.0,步长为 0.1)上计算平均准确率。 由于原始数据通常不会恰好落在这些召回率点上,因此我们采用插值准确率(interpolated precision):对于每个目标召回率 $r$,取所有大于或等于 $r$ 的召回率位置中准确率的最大值作为该点的插值结果。 换句话说,
$$ \text{IntPrecision}(r) = \max_{i \geq r} \text{Precision}(i) \tag{11.14} $$这种插值方法不仅使我们能够对多个查询的性能取平均,还能平滑原始数据中因排序波动导致的不规则准确率变化。 其设计初衷是“对系统从宽处理”——在评估某一召回率水平时,赋予系统在其更高召回率处所达到的最佳准确率。 图 11.5 和图 11.6 展示了基于前述示例数据得到的插值结果。
| 插值准确率 | 召回率 |
|---|---|
| 0.66 | 0.20 |
| 0.66 | 0.30 |
| 0.66 | 0.40 |
| 0.63 | 0.50 |
| 0.55 | 0.60 |
| 0.47 | 0.70 |
| 0.44 | 0.80 |
| 0.36 | 0.90 |
| 0.36 | 1.0 |
图 11.5 基于图 11.3 数据计算出的插值点。
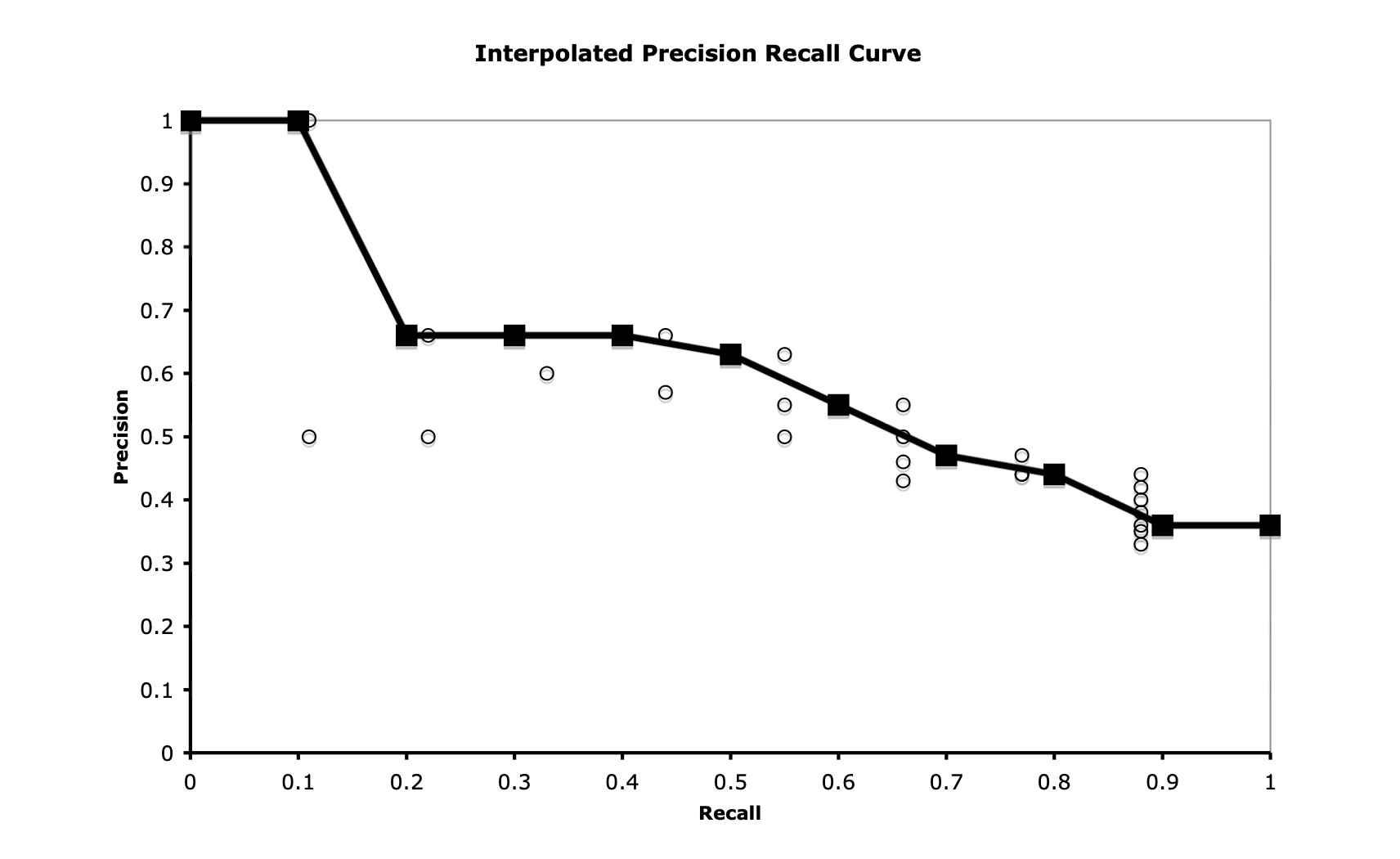
图 11.6 一条 11 点插值的准确率-召回率曲线。 在每个标准召回率水平(共 11 个)上,准确率通过对该召回率及以上所有位置中的最大准确率进行插值得到。 图中也同时标出了原始测量点。
有了如图 11.6 所示的曲线,我们就可以通过比较不同系统的曲线来评估其优劣。 显然,在所有召回率水平上准确率更高的曲线更优。 此外,这些曲线还能揭示系统整体的行为倾向。 在左侧(低召回率区域)准确率更高的系统,倾向于优先保证精度;在右侧(高召回率区域)表现更好的系统,则更侧重于提高召回能力。
另一种评估排序检索系统的方法是平均准确率均值(Mean Average Precision, MAP),它提供了一个单一数值指标,便于直接比较不同系统或方法。 在 MAP 方法中,我们同样从上到下遍历排序结果列表,但仅在遇到相关文档的位置记录准确率(例如在图 11.3 中,只在排名 1、3、5、6 处记录,而跳过 2、4 等不相关位置)。 对于单个查询,我们将这些位置上的准确率取平均(通常可设定一个截断上限)。 形式化地,设 $R_r$ 为在排名 $r$ 及之前返回的相关文档集合,则该查询的平均准确率(Average Precision, AP)定义为:
$$ AP = \frac{1}{|R_r|} \sum_{d \in R_r} \text{Precision}_r(d) \tag{11.15} $$其中,$\text{Precision}_r(d)$ 表示文档 $d$ 被返回时所在排名位置处的准确率。 对于包含多个查询的集合 $Q$,我们再对所有查询的 AP 值取平均,得到最终的 MAP 指标:
$$ MAP = \frac{1}{|Q|} \sum_{q \in Q} AP(q) \tag{11.16} $$图 11.3 所示的单个查询的 MAP(此时即为 AP)值为 0.6。