我们已经了解了大语言模型(LLM)的三个训练层次:预训练,在此阶段模型学习预测单词;以及两种后训练方法:指令调优,在此阶段模型学习遵循指令;和偏好对齐,在此阶段模型学习倾向于人类偏好的提示延续。
然而,在这些步骤之后,甚至在推理阶段,即当模型生成输出时,我们还可以进行一些后训练计算。 这类后训练任务被称为推理时计算。 这里我们将重点介绍一个代表性例子— — 思维链提示(Chain-of-Thought Prompting)。
10.4.1 思维链提示
有多种技术可以利用提示来提高语言模型在许多任务上的表现。 这里我们描述其中一种称为思维链提示的技术。
思维链提示的目标是改善语言模型在那些通常难以解决的推理任务上的表现。 其原理是,人们通过将复杂问题分解为多个步骤来解决问题,因此我们希望提示中的文本能够鼓励语言模型以类似的方式分解问题。
实际技术非常简单:在少样本提示中的每个示例都会增加一些解释某些推理步骤的文本。 目标是促使语言模型针对正在解决的问题输出类似的推理步骤,并让这些推理步骤的结果引导系统生成正确答案。
实际上,多项研究表明,通过这种方式在演示中添加推理步骤可以使语言模型更有可能给出复杂推理任务的正确答案(Wei 等人,2022年;Suzgun 等人,2023b)。 图 10.10 展示了一个在数学应用题领域(来自Cobbe等人的GSM8k数据集)使用思维链文本增强演示的例子。 图 10.11 展示了来自 BIG-Bench-Hard 数据集(Suzgun 等人,2023b)中的一个类似例子。
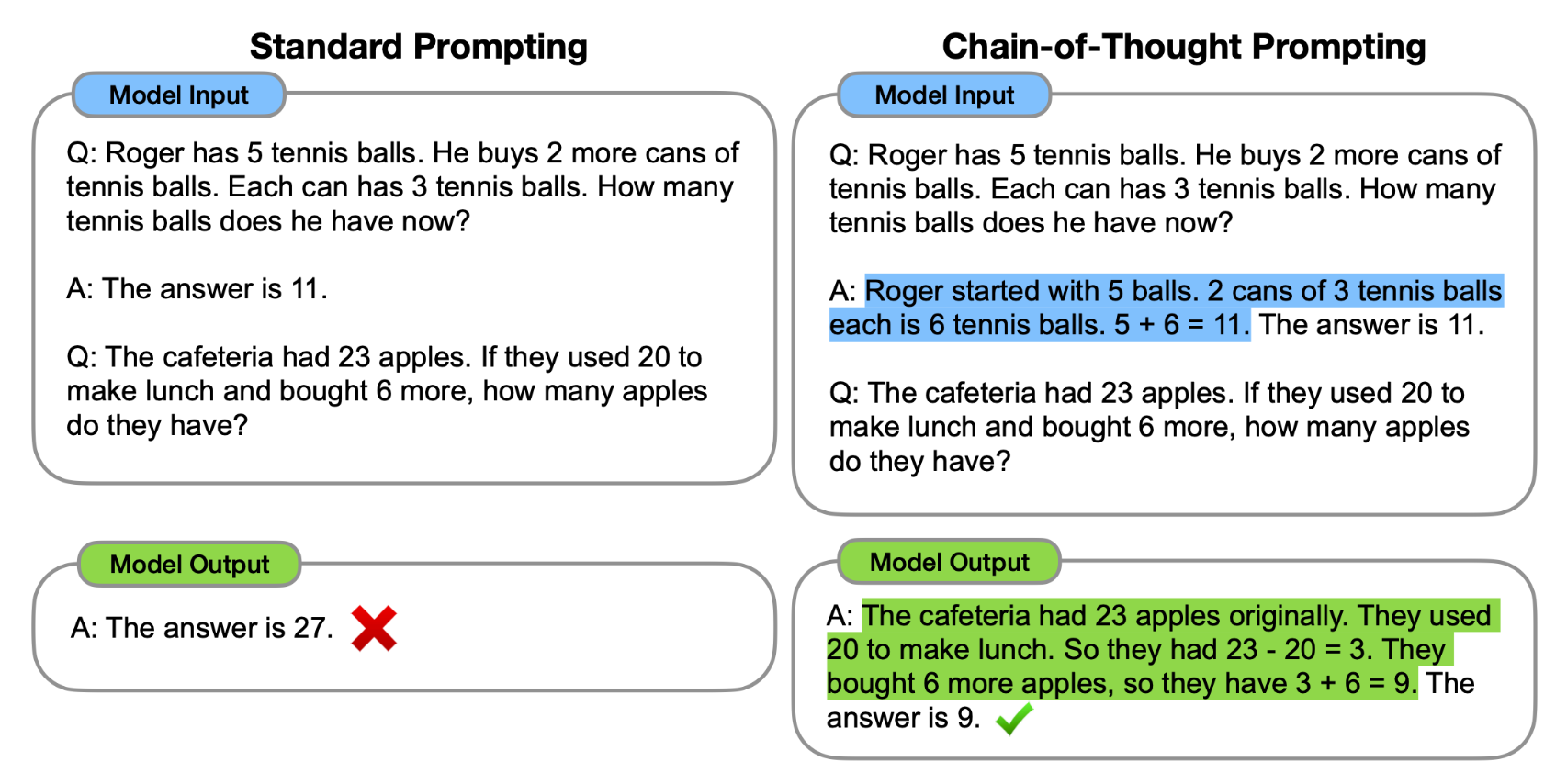
图10.10 在数学应用题中使用思维链提示(右侧)与标准提示(左侧)的例子。来自Wei等人的研究(2022年)。
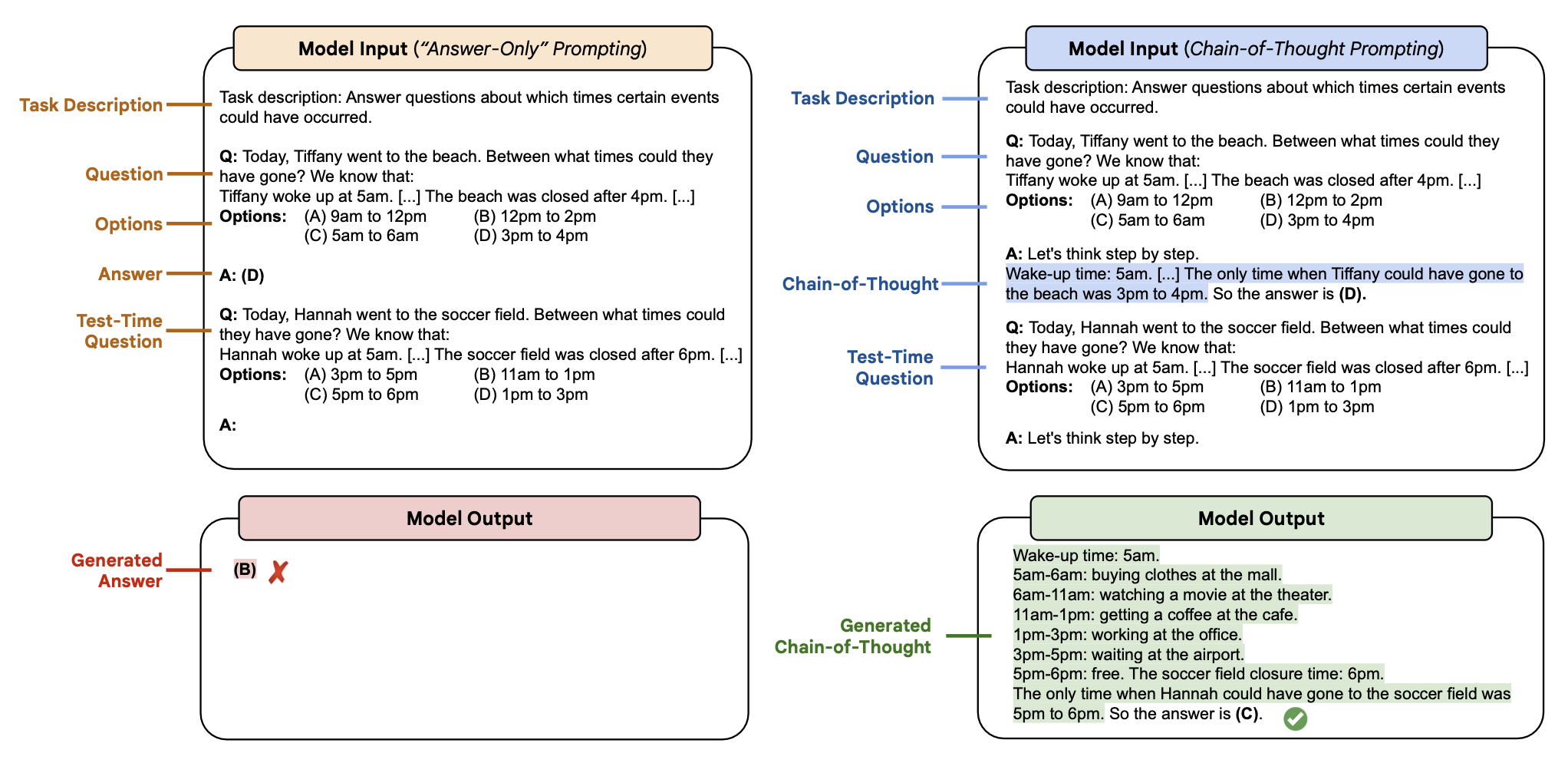
图10.11 在时间序列推理任务中使用思维链提示(右侧)与标准提示(左侧)的例子。来自Suzgun等人的研究(2023b)。