当前利用偏好数据对齐大语言模型(LLM)的方法,主要基于强化学习(Reinforcement Learning, RL)框架(Sutton 和 Barto, 1998)。 在强化学习设定中,模型根据当前状态的特征,通过策略(policies)选择一系列动作。 环境会对每个动作提供一个奖励,而整个动作序列的总奖励是该序列中各动作奖励的函数。 强化学习的目标是在一段训练周期内最大化累积奖励。 将强化学习应用于优化 LLM 时,我们采用如下对应关系:
- 动作(Actions):对应自回归生成过程中每一步所选择的词元(token);
- 状态(States):对应当前解码步骤的上下文,即到该时刻为止已生成的词元序列;
- 策略(Policies):对应以预训练 LLM 形式体现的概率语言模型;
- 奖励(Rewards):基于从偏好数据中学得的奖励模型,对 LLM 的输出进行打分。
按照这一强化学习框架,我们将预训练的 LLM 称为策略 $\pi$,并将提示与输出对应的偏好得分称为奖励 $r(x,o)$。 我们的目标是训练一个策略 $\pi_\theta$,使其在给定由偏好数据导出的奖励模型下,最大化其生成输出的奖励。 换句话说,我们希望经过偏好训练的 LLM 能够生成奖励高的输出。 这可以表示为以下优化问题:
$$ \pi^* = \underset{\pi_\theta}{\operatorname{argmax}} \; \mathbb{E}_{x \sim D,\, o \sim \pi_\theta(o|x)} [\, r(x,o) \,] \tag{10.4} $$在此公式中,我们从一组相关的训练提示中采样提示 $x$,从当前策略 $\pi_\theta$ 中采样输出 $o$,并评估每个样本的奖励。 训练样本上的平均奖励即为策略 $\pi_\theta$ 的期望奖励,而我们的目标是找到能最大化该期望奖励的策略(即模型)。
然而,将强化学习用于 LLM 对齐与传统强化学习存在两个关键差异。 第一,传统 RL 中的奖励信号来自环境,反映的是动作结果的客观事实(例如“你赢了游戏”或“你输了”)。 而在偏好学习中,奖励模型只是对真实奖励的一种有噪声的代理(noisy surrogate),它本身是从人类偏好中学习得到的近似。
第二,学习的起点不同。 典型的 RL 应用通常从零开始学习最优策略,即从一个随机初始化的策略出发。 而在这里,我们起点是一个已经具备强大能力的模型 —— 它已在海量数据上完成预训练,又经过指令微调,最后才用偏好数据进一步优化。 因此,目标并非彻底改变模型的行为,而是温和地引导(nudge)其向更受偏好的行为靠拢。
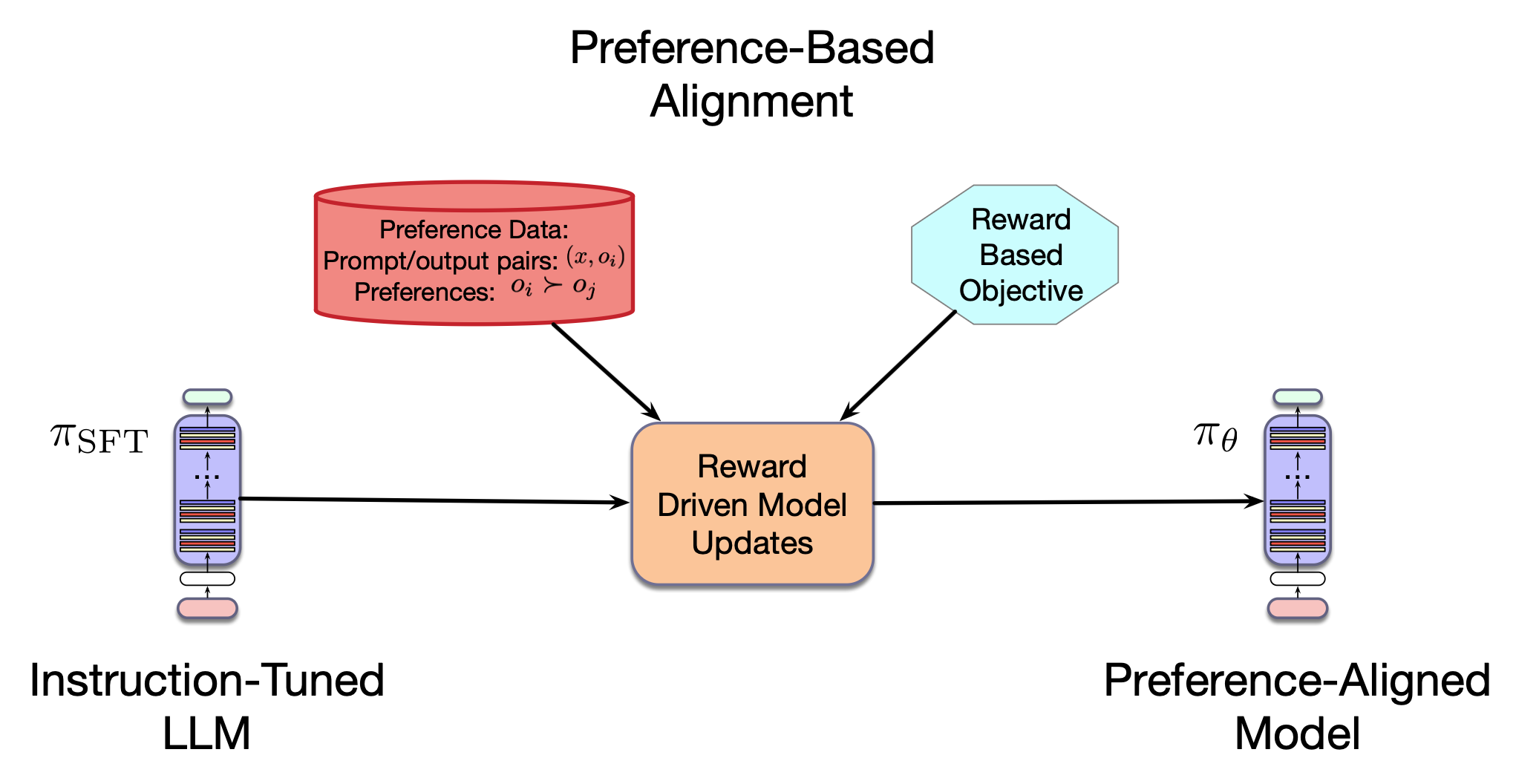
图 10.8 基于偏好的模型对齐。
正因如此,如果我们直接按公式 (10.4) 优化奖励,预训练 LLM 往往会“遗忘”其在预训练阶段学到的大量知识,转而过度拟合规模相对较小的偏好数据,只为追求更高的奖励分数。 为避免这一问题,我们在奖励函数中加入一项惩罚项,以防止新策略偏离初始模型过远:
$$ \pi^* = \underset{\pi_\theta}{\operatorname{argmax}} \; \mathbb{E}_{x \sim D,\, o \sim \pi_\theta(o|x)} \left[\, r(x,o) - \beta \, \mathbb{D}_{\mathrm{KL}} \big( \pi_\theta(o|x) \,\|\, \pi_{\text{ref}}(o|x) \big) \right] \tag{10.5} $$公式中的第二项 $\mathbb{D}_{\mathrm{KL}}(\pi_\theta(o|x) \,\|\, \pi_{\text{ref}}(o|x))$ 是KL 散度(Kullback-Leibler divergence)。 简单来讲,KL 散度用于衡量两个概率分布之间的距离。 超参数 $\beta$ 控制该项惩罚的强度。 对于基于 LLM 的策略,KL 散度可展开为新策略与参考策略 $\pi_{\text{ref}}$ 之间对数概率比的期望。
$$ \pi^* = \underset{\pi_\theta}{\operatorname{argmax}} \; \mathbb{E}_{x \sim D,\, o \sim \pi_\theta(o|x)} \left[\, r_\phi(x,o) - \beta \log \frac{\pi_\theta(o|x)}{\pi_{\text{ref}}(o|x)} \right] \tag{10.6} $$在接下来的章节中,我们将探讨两种基于此优化框架的 LLM 对齐方法。 第一种方法使用偏好数据训练一个显式的奖励模型,再结合强化学习算法,依据公式 (10.6) 优化语言模型; 第二种方法则通过对公式 (10.6) 的闭式解进行巧妙重排,直接利用现有偏好数据对模型进行微调,无需显式构建奖励模型。
10.3.1 强化学习与偏好反馈(PPO)
待续
10.3.2 直接偏好优化
直接偏好优化(Direct Preference Optimization, DPO)(Rafailov等人,2023)采用基于梯度的学习方法,利用偏好数据优化候选的大语言模型(LLM),而无需学习显式的奖励模型或从正在更新的模型中采样。 根据Bradley-Terry模型,在给定提示和相应的输出时,偏好对的概率是两个选项奖励差值的逻辑斯蒂Sigmoid函数。 在强化学习框架中,分数 $z$ 由奖励模型针对提示及其对应的输出提供。
$$ \begin{align*} P(o_i \succ o_j|x) &= \sigma(z_i - z_j) \tag{10.7} \\ &= \sigma(r(x,o_i) - r(x,o_j)) \tag{10.8} \end{align*} $$DPO 始于前面提到的带有 KL 约束的最大化公式(10.6),该公式用奖励模型和参考模型 $\pi_{\text{ref}}$ 来表达最优策略 $\pi^*$。 DPO 的关键思想在于重写这个最大化问题的闭式解,以表示奖励函数 $r(x,o)$ 关于最优策略 $\pi^*$ 和参考策略 $\pi_{\text{ref}}$ 的形式。
$$ r(x,o) = \beta \log \frac{\pi_r(o|x)}{\pi_{\text{ref}}(o|x)} + \beta \log Z(x) \tag{10.9} $$其中 $Z(x)$ 是一个配分函数 —— 对于给定提示 $x$ 的所有可能输出 $o$ 的总和。
$$ Z(x) = \sum_y \pi_{\text{ref}}(o|x)\exp\left(\frac{1}{\beta} r(x,o)\right) \tag{10.10} $$由于配分函数中的求和使得其直接使用变得不切实际。 然而,由于Bradley-Terry模型基于的是项间奖励的差异,将公式(10.9)代入(10.7)后,配分函数相互抵消,得到如下表达:
$$ \begin{align*} P(o_i \succ o_j|x) &= \sigma(r(x,o_i)-r(x,o_j)) \tag{10.11} \\ &= \sigma\left(\beta \log \frac{\pi_\theta (o_i|x)}{\pi_{\text{ref}}(o_i|x)} - \beta \log \frac{\pi_\theta (o_j|x)}{\pi_{\text{ref}}(o_j|x)}\right) \tag{10.12} \end{align*} $$通过这种变换,DPO 将偏好对的可能性表示为两个 LLM 策略的关系,而不是依赖于一个显式的奖励模型。 因此,单个实例的交叉熵损失(负对数似然)为:
$$ L_{\text{DPO}}(x,o_w,o_l) = -\log \sigma \left(\beta \log \frac{\pi_{\theta}(o_w|x)}{\pi_{\text{ref}}(o_w|x)} - \beta \log \frac{\pi_{\theta}(o_l|x)}{\pi_{\text{ref}}(o_l|x)}\right) $$在整个训练集 $\mathbb{D}$ 上的损失由以下期望给出:
$$ L_{\text{DPO}}(\pi_{\theta}) = -\mathbb{E}_{(x,o_w,o_l)\sim D}\left[\log \sigma\left(\beta \log \frac{\pi_{\theta}(o_w|x)}{\pi_{\text{ref}}(o_w|x)} - \beta \log \frac{\pi_{\theta}(o_l|x)}{\pi_{\text{ref}}(o_l|x)}\right)\right] $$这个损失函数源自Sigmoid函数的导数,并且直接类比于 10.2.3 节中介绍的使用 Bradley-Terry 框架学习奖励模型的方法。 实际上,这种损失函数的设计及其相应的基于梯度的更新规则,增加了优选选项的概率并降低了非优选选项的概率。 它通过 KL 惩罚平衡了这一目标,防止偏离 $\pi_{\text{ref}}$ 过多。 $\beta$ 是一个超参数,控制惩罚项的强度;通常取值范围为 0.1 到 0.01。
如图 10.9 所示,DPO 使用此损失函数和可用的训练数据进行梯度下降,以优化策略 $\pi_{\theta}$,该策略初始化自现有的预训练、微调的 LLM。
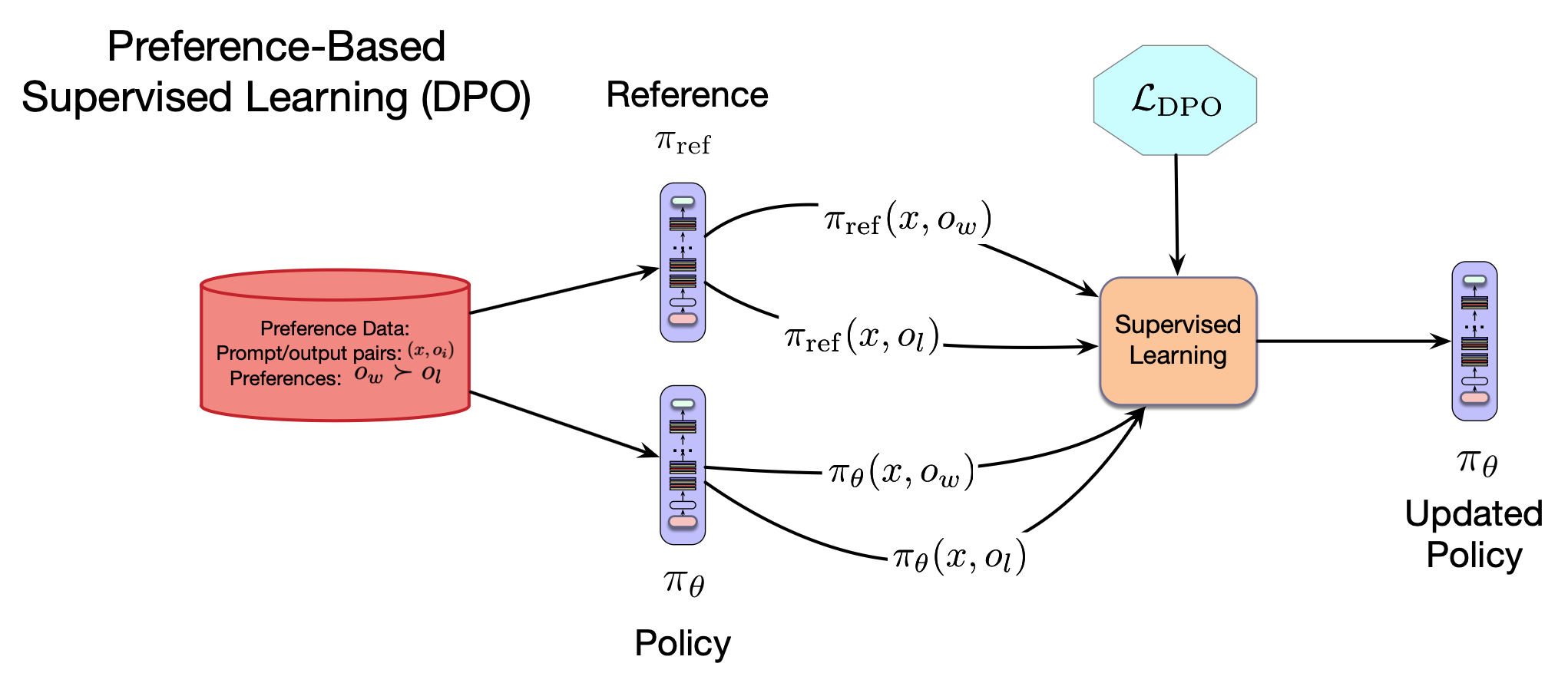
图10.9 使用直接偏好优化的基于偏好的对齐。
与10.3.1节中描述的显式基于RL的方法PPO相比,DPO有几个优势:
- DPO不需要训练显式的奖励模型。
- DPO直接从包含在 $\mathbb{D}$ 中的偏好中学习,无需计算昂贵的在线采样 $\pi_{\theta}$。
- 在训练过程中,DPO 只需维护 2 个 LLM,而 PPO 需要 4 个模型。