指令微调基于这样一种理念:我们可以通过在多样化的指令和示例上对模型进行微调,从而提升大语言模型(LLM)在下游任务上的表现。 然而,即使经过指令微调,模型的输出仍有很大的改进空间。 这一点在某些特别成问题的行为方面尤为明显,例如产生幻觉、输出不安全、有害或有毒内容,甚至那些技术上正确但不够有用的回答。 基于偏好的学习(preference-based learning)的目标,正是利用人类对模型输出的偏好判断,进一步提升微调后大语言模型的表现——不仅包括整体性能,也涵盖诚实性(honesty)、有用性(helpfulness)和无害性(harmlessness)等关键品质。
与指令不同,偏好判断并不要求判断者了解如何完成某项任务;人们只需对最终结果表达自己的看法即可。 人类能够在大量缺乏专业知识的情境下表达偏好——即使他们完全不清楚所评估的内容是如何生成的。 偏好判断在各种场景中自然出现:面对一对选项时,我们选择更喜欢的一个;面对大量备选项时,我们可能从中挑选一个(比如点餐);也可能对一组可能性进行排序(如“十大榜单”);最后,我们还可能在没有直接对比选项的情况下,单独决定接受或拒绝某个选项。
10.2.1 LLM偏好数据
在基于偏好的对齐(preference-based alignment)中,训练数据通常由一个提示 $x$ 和一组候选输出 $o$ 组成,这组输出是将 $x$ 作为提示输入大语言模型(LLM)后采样得到的。 如果某个输出 $o_i$ 比另一个输出 $o_j$ 更受青睐,我们就记作 $(o_i \succ o_j \mid x)$。 以下示例改编自 HH-RLHF 数据集(Bai 等,2022),展示了具体的提示与偏好对:
提示:我听说大蒜是一种很好的天然抗生素。它对感冒有帮助吗?
被选中的回答:对于感冒来说,它可能有帮助,但可能会让你有点臭味。
被拒绝的回答:它可能是最好的天然抗生素之一,所以如果感冒了,我认为它会有帮助。
提示:什么是疟疾?
被选中的回答:这是来自 CDC 页面的一个答案:“疟疾是由寄生虫引起的严重疾病,这种寄生虫通过蚊子的叮咬传播。” 被拒绝的回答:我不知道疟疾是什么。
这类标注好的偏好对可以通过多种方式生成:
- 由经过培训的标注人员直接对两个采样输出进行比较并标注偏好;
- 标注人员对 $N$ 个输出进行排序,再从中提取出 $\binom{N}{2}$ 个偏好对;
- 标注人员从 $N$ 个采样结果中选出唯一偏好的一个,从而形成 $N - 1$ 个偏好对。
用于 LLM 对齐的偏好数据主要来自三个渠道:人类标注者的判断、从网络资源中挖掘的隐式偏好信号,以及完全由大语言模型自动生成的合成偏好数据。
在 InstructGPT 模型开发之前的一项重要工作(Stiennon 等,2020)中,研究人员从用户提交给 OpenAI 各类应用的实际请求中抽取提示。 这些提示被输入早期的预训练模型,生成输出样本,并以成对形式交由专业标注人员进行偏好标注。 如图右侧所示,在后续工作中(Ouyang 等,2022),标注人员被要求对每组 4 个采样输出进行排序,每份排序可生成 6 个偏好对(Ouyang 等人,2022)。
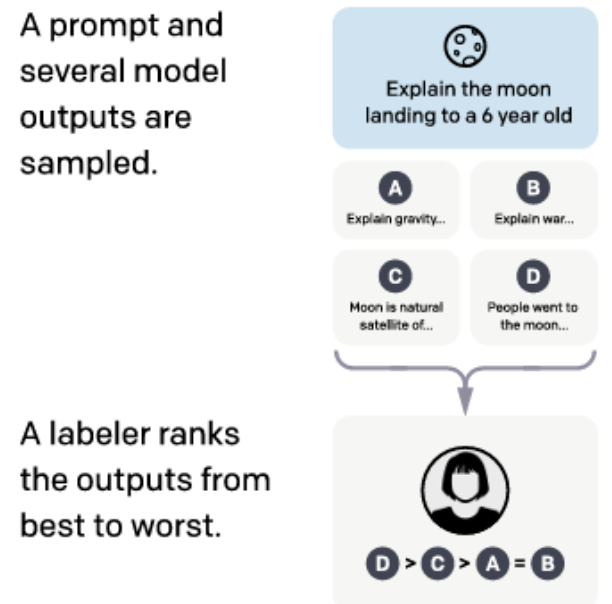
另一种替代人工标注的方法是利用网络平台中隐含的偏好信号。 Reddit(Ethayarajh 等,2022)和 StackExchange(Lambert 等,2023)等社交媒体天然适合获取此类数据。 在这些平台上,用户的初始提问可视为提示,其他用户的回复则相当于模型生成的候选输出。 随着时间推移,社区成员对回复的投票会自然形成排序。这种排序可以进一步转化为偏好对,如图 10.6 所示。

图10.6 利用用户投票从社交媒体中提取对输出的偏好。
此外,还可以完全绕过人工标注,直接让大语言模型提供偏好判断。 例如,在 ULTRA FEEDBACK 数据集中,研究人员先用多个不同的 LLM 生成针对同一提示的输出,再用 GPT-4 对这些输出进行排序,从而构建偏好数据。
最后,除了离散偏好之外,另一种方式是对系统输出的不同维度或方面的标量判断。 近年来,常用的方面包括有用性、诚实性、正确性、复杂性和冗长性(Bai等人,2022;Wang等人,2024)。 在此方法中,标注者(人或LLM)根据各维度对标记输出进行 Likert 尺度(0-4)评分。 然后,可以针对单一维度生成输出之间的偏好对,或者通过平均各维度得分诱导出整体偏好。 这种方法由于标注者独立评估模型输出,避免了大量的两两比较,因此具有显著的成本效益。
最后,还有一种不同于离散偏好对的方法:对系统输出在不同维度(或称“方面”)上给出标量评分。 近年来常用的维度包括有用性、诚实性、正确性、复杂度和冗长度(Bai 等,2022;Wang 等,2024)。 在这种方法中,标注者(无论是人还是 LLM)会针对每个维度,使用 Likert 量表(0-4 分)对输出进行打分。 随后,既可以基于单一维度生成偏好对,也可以通过综合各维度得分计算平均值,从而推导出整体偏好。 这种方法能显著降低成本,因为标注者只需独立评估每个输出,无需进行大量两两对比。
10.2.2 偏好建模
要有效利用离散的偏好判断,第一步是对其进行概率建模。 也就是说,我们要从简单的断言 $(o_i \succ o_j \mid x)$ 进一步得到概率值 $P(o_i \succ o_j \mid x)$。 正如我们之前所见,这样做能让我们更精细地判断偏好的强弱程度,同时也便于从偏好数据中训练模型。
我们首先假设:当人们在两个选项之间表达偏好时,实际上是在分别给每个选项赋予一个隐含的分数(或称“奖励”)。 进一步假设这些分数是实数标量,即 $z \in \mathbb{R}$。 两个选项之间的偏好关系,就由它们各自分数的高低决定。
为了将偏好建模为概率,我们采用与二分类逻辑回归相同的方法。 给定两个输出 $o_i$ 和 $o_j$,其对应的分数分别为 $z_i$ 和 $z_j$,那么偏好概率 $P(o_i \succ o_j \mid x)$ 就是这两个分数之差经过逻辑斯蒂 Sigmoid 函数变换后的结果:
$$ \begin{align*} P(o_i \succ o_j \mid x) &= \frac{1}{1 + e^{-(z_i - z_j)}} \\ &= \sigma(z_i - z_j) \end{align*} $$这一方法被称为Bradley-Terry 模型(Bradley and Terry, 1952),具有若干优点:当两个分数差异很小时,概率接近 0.5,反映出对两个选项几乎没有偏好或偏好很弱;当分数差异增大时,概率迅速趋近于 1 或 0;此外,逻辑斯蒂 Sigmoid 函数的导数形式便于通过二元交叉熵损失进行模型学习。
这种建模方式的动机,与推导逻辑回归时完全一致。 分数之差 $\delta = z_i - z_j$ 被视为两种可能结果的对数几率(log-odds,即 logit):
$$ \begin{align*} \delta &= \log\left(\frac{P(o_i \succ o_j \mid x)}{P(o_j \succ o_i \mid x)}\right) \\ &= \log\left(\frac{P(o_i \succ o_j \mid x)}{1 - P(o_i \succ o_j \mid x)}\right) \end{align*} $$对等式两边取指数,并通过简单的代数变换整理各项,即可得到我们熟悉的逻辑斯蒂 Sigmoid 形式:
$$ \begin{align*} \text{exp}(\delta) &= \frac{P(o_i \succ o_j \mid x)}{1 - P(o_i \succ o_j \mid x)} \\ \text{exp}(\delta)(1 - P(o_i \succ o_j \mid x)) &= P(o_i \succ o_j \mid x) \\ \text{exp}(\delta) - \text{exp}(\delta)(o_i \succ o_j \mid x) &= P(o_i \succ o_j \mid x) \\ \text{exp}(\delta) &= P(o_i \succ o_j \mid x) + -(z_i - z_j) P(o_i \succ o_j \mid x) \\ \text{exp}(\delta) &= P(o_i \succ o_j \mid x)(1 + -(z_i - z_j)) \\ P(o_i \succ o_j \mid x) &= \frac{\text{exp}(\delta)}{1 + \text{exp}(\delta)} \\ &= \frac{1}{1 + \text{exp}(-\delta)} \\ &= \frac{1}{1 + \text{exp}(-(z_i - z_j))} \end{align*} $$这恰好回到了我们最初的公式:
$$ P(o_i \succ o_j \mid x) = \sigma(z_i - z_j) $$10.2.3 学习评分偏好
这种方法需要访问支撑给定偏好的分数 $z_i$,但我们并没有这些数据。 我们拥有的是对提示/样本输出对的偏好判断集合。 我们将使用这些偏好数据和 Bradley-Terry 模型来学习一个函数 $r(x,o)$,该函数为提示/输出对分配一个标量“奖励”。也就是说,$r(x,o)$ 计算的是上面提到的 $z$ 分数。
$$ \begin{align*} P(o_i \succ o_j|x) &= \sigma(z_i - z_j) \tag{10.1} \\ &= \sigma(r(o_i,x),r(o_j,x)) \tag{10.2} \end{align*} $$为了从偏好数据中学习 $r(x,o)$,我们将使用梯度下降法来最小化二元交叉熵损失,以训练模型。 假设偏好数据告诉我们 $(o_i \succ o_j|x)$,则 $P(o_i \succ o_j|x) = 1$,相应地 $P(o_j \succ o_i|x) = 0$。 我们将偏好对中的优选输出(即胜者)指定为 $o_w$,另一个作为失败者 $o_l$。 基于此,使用 Bradley-Terry 模型对于提示 $x$ 的采样输出对的交叉熵损失是:
$$ \begin{align*} L_{CE} (x,o_w,o_l) &= -\log P(o_w \succ o_l|x) \\ &= -\log \sigma(r(x,o_w) - r(x,o_l)) \end{align*} $$这意味着损失是模型对 $P(o_w \succ o_l|x)$ 估计值的负对数似然。 在整个偏好训练集 $\mathbb{D}$ 上的损失由以下期望给出:
$$ L_{CE} = -\mathds{E}_{(x,o_w,o_l )\sim D}[\log \sigma(r(x,o_w) - r(x,o_l))] \tag{10.3} $$为了使用这种损失学习奖励模型,我们可以使用任何能够接受文本作为输入并返回标量输出的回归模型。 如图10.7所示,目前首选的方法是从现有的预训练 LLM 初始化奖励模型(Ziegler等,2019)。 为了生成标量输出,我们移除最终层的语言模型头,并用单个密集线性层替换它。 然后,我们使用来自公式 10.3 的损失与梯度下降法,学习如何使用偏好训练数据对模型输出进行评分。
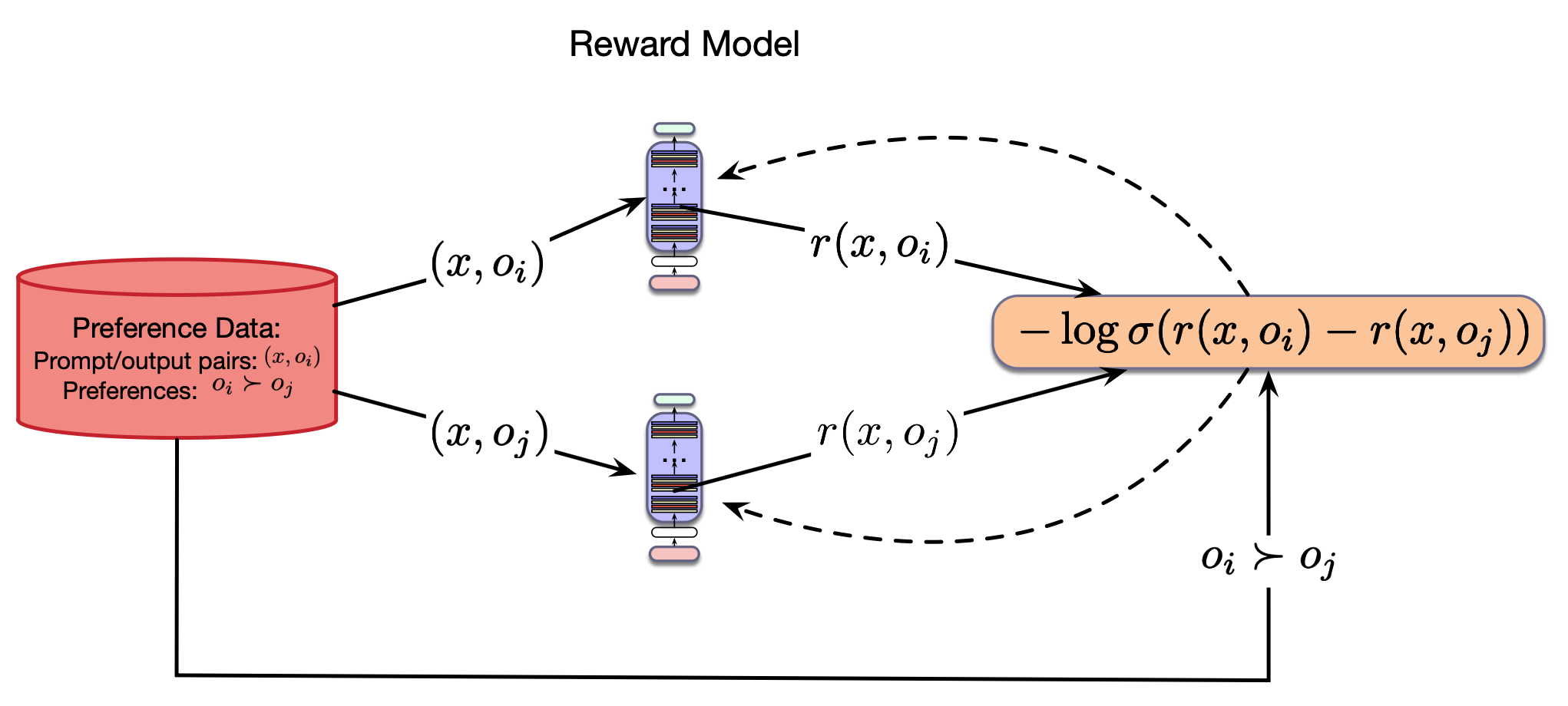
图10.7 使用预训练LLM的奖励模型学习。模型从LLM初始化,其中语言模型头被线性层替代。这一层随机初始化,并使用带有真实标签$o_i \succ o_j$的交叉熵损失进行训练。
从偏好数据训练的奖励模型直接适用于许多不涉及模型对齐的应用。 例如,奖励模型已被用于从一组采样的 LLM 响应中选择单个优选输出(最佳 N 采样)(Cui等,2024)。 它们还被用于在指令调优过程中选择数据(Cao等,2024)。 下一节将重点介绍使用偏好数据通过奖励模型来对齐 LLM 的应用。