指令微调(instruction tuning,有时甚至简称为instruct tuning)是一种让大语言模型(LLM)更好地遵循指令的方法。 该方法获取一个基础的预训练大语言模型,通过在一组包含指令和响应的语料上进行微调,使其学会遵循指令,执行从机器翻译到餐饮计划等一系列任务。 最终得到的模型不仅学会了这些特定任务,还进行了一种元学习,总体上提升了其遵循指令的能力。
指令微调是一种监督学习方法,其中训练数据由指令组成,我们使用与训练原始模型相同的语言模型目标继续对模型进行训练。 对于因果模型而言,这就是标准的预测下一个标记的目标。 指令训练语料被简单地视为额外的训练数据,如同在原始模型训练中一样,使用交叉熵损失生成基于梯度的更新。 尽管该方法训练模型预测下一个标记(这通常被认为是一种自监督),由于指令微调数据中每个指令或问题都有一个监督目标——即问题的正确答案或对指令的响应,因此我们称这种方法为监督微调(supervised fine-tuning, SFT)。
那么,指令微调与其他在第 7 章和第 10 章介绍的微调方式有何不同? 图10.1概述了它们之间的差异。 在第一个例子中,正如第 7 章所介绍的,我们可以在新领域的数据上,仅继续预训练大语言模型,就可以来实现微调以适应新领域。 在这种方法中,大语言模型的所有参数都会被更新。
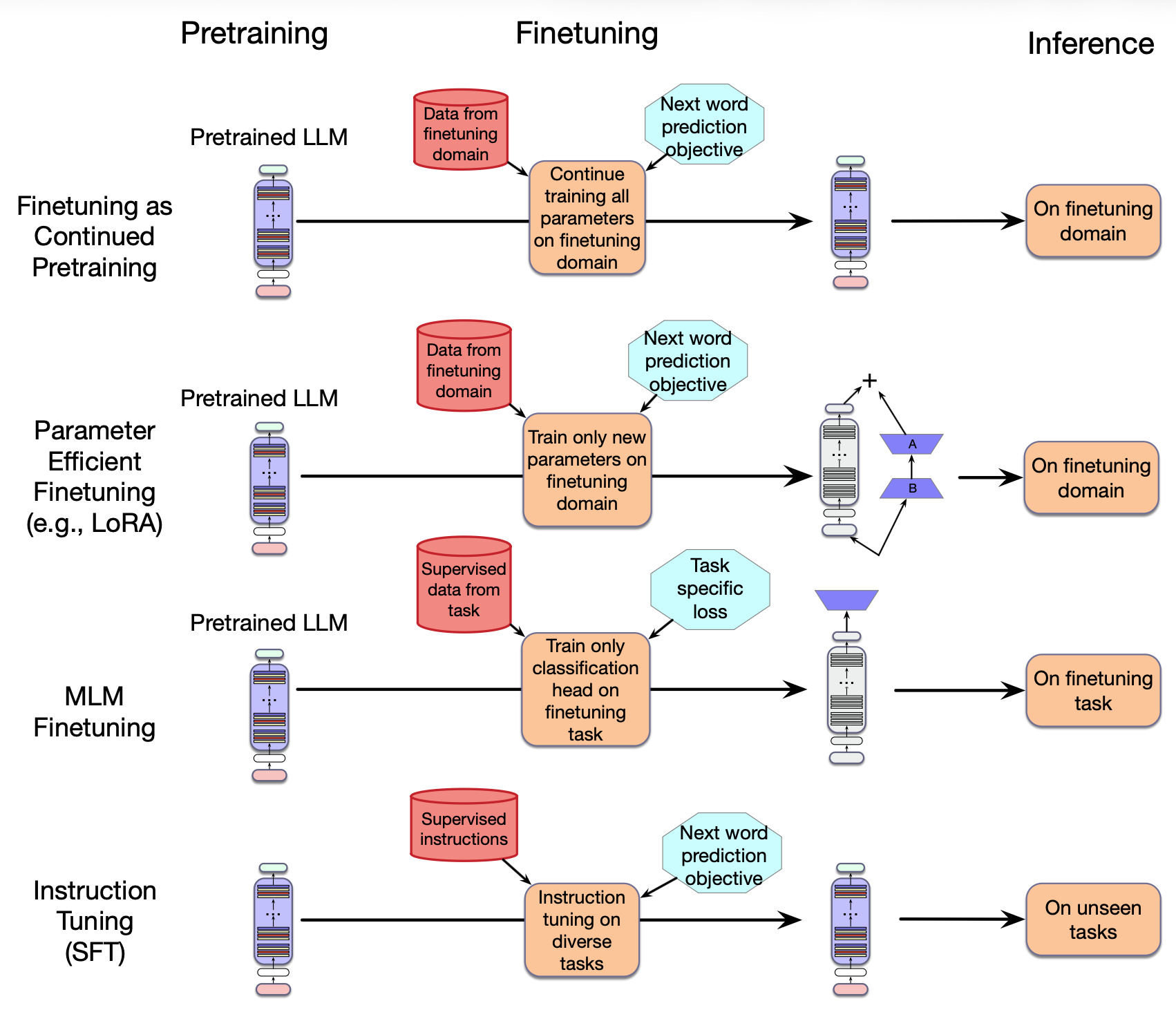
图10.1 指令微调与其他类型的微调对比。
在第二个例子中,同样是来自第 7 章的参数高效微调,我们创建一些新的(小量的)参数,仅调整这些参数来适应新领域。 例如,在 LoRA 中,我们调整的是 A 矩阵和 B 矩阵,而预训练模型的参数则保持冻结状态。
在第 10 章的任务型微调中,我们添加一个新的专门分类头,有自己的损失函数(如分类或序列标注)来更新特征,目标是适应特定任务;预训练模型的参数保持冻结状态,也可能稍作更新。
最后,在指令微调中,我们采用一组指令及其监督响应的数据集,并基于标准的语言模型损失继续训练语言模型。
像所有这些类型的微调一样,指令微调相较于基础大语言模型的训练要温和得多。 训练通常涉及数千条指令数据集上的几个周期。 因此,指令微调的整体成本只是训练基础模型原始成本的一小部分。
10.1.1 指令作为训练数据
提到“指令”时,我们指的是用自然语言描述要执行的任务,结合了带标记的任务演示。 这可以包括类似于我们已经看到的提示的最小描述,例如“回答下列问题”,“将以下文本翻译成阿拉帕霍语”,或“总结这份报告”。 在纯预训练模型中,我们只能依赖简单提示来激发其已有能力;但现在要通过监督微调来更新模型,指令完全可以更加丰富,而不必拘泥于那种简单的唤醒式提示。 还可以包含长度限制或其他约束、需要扮演的角色,以及演示。
人们已经创建了许多庞大的指令微调数据集,涵盖了众多任务和语言。 例如,Aya 在 114 种语言中提供了来自12个任务(包括问答、总结、翻译、释义、情感分析、自然语言推理等其他6个任务)的5.03亿条指令(Singh等人, 2024)。 SuperNatural Instructions 拥有来自 1600 个任务的 1200 万例子(Wang等人, 2022),Flan 2022 包含了来自1836个任务的 1500 万例子(Longpre等人, 2023),而 OPT-IML 则有来自 2000 个任务的 1800 万例子(Iyer 等人, 2022)。
这些指令微调数据集通过四种方式创建。 第一种是人们直接编写实例。 例如,Aya 指令微调语料库的一部分(图 10.2)包含了由 65 种语言中的 3000 名流利说话者自愿撰写的 20.4 万个指令/响应实例,这是参与式研究计划的一部分,目的是提高大型语言模型的多语言性能。

图10.2 Aya 语料库中 65 种语言中的 4 种语言的提示/完成实例样本(Singh等人, 2024)。
以这种方式开发高质量的监督训练数据既耗时又昂贵。 一种更常见的方法是利用多年来为广泛的自然语言处理任务策划的大量监督训练数据。 存在数千个这样的数据集,如 SQuAD 的问题与答案数据集(Rajpurkar等人, 2016)或众多翻译或摘要的数据集。 这些数据可以通过简单的模板,自动转换为指令提示和输入/输出演示对。
图 10.3 展示了来自 SUPER NATURAL INSTRUCTIONS 资源的一些应用示例(Wang等人, 2022),显示了相关的字段如 text(文本)、context(上下文)和* hypothesis*(假设)。 为了生成指令微调数据,从训练数据中提取这些字段和真实标签,编码为键/值对,并插入模板(图 10.4)以生成实例化指令。 因为提示用词多样化是有益的,语言模型也可以用于生成提示的释义。
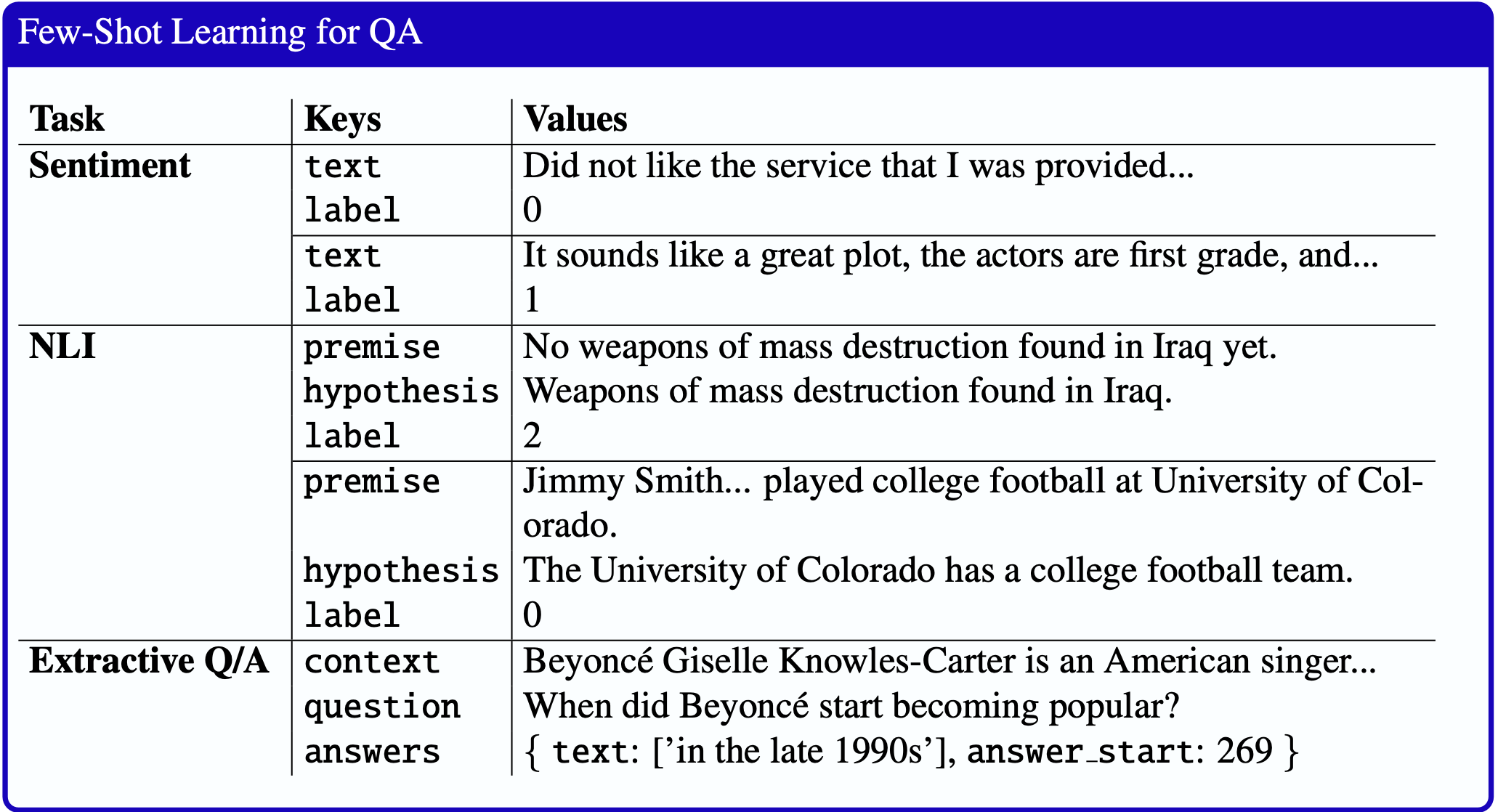
图10.3 情感分析、自然语言推断和问答任务的监督训练数据示例。 从数据集中提取各种组件并存储为键/值对,以便用于生成指令。

图10.4 情感分析、问答和 NLI 任务的指令模板。
由于监督 NLP 数据集本身通常是由众包工作者根据精心编写的注释指南生产的,因此第三种选择是利用这些指南,其中可以包括详细的逐步说明、需避免的陷阱、格式说明、长度限制、范例等。 这些注释指南可以直接用作语言模型的提示,以创建指令微调训练示例。 图 10.5 展示了一个被重新用作语言模型提示的众包工作者注释指南,用于创建指令微调数据(Mishra等人, 2022)。 该指南描述了一项问答任务,其中标注者根据给定的扩展段落提供问题的答案。
示例:扩展型指令
任务定义:
本任务要求根据给定的段落,回答复杂的提问。这类问题通常需要理解多个句子才能作答。请确保你的答案类型与输入中指定的“答案类型”一致。
可能的“答案类型”包括以下三类:“span”(片段)、“date”(日期)或“number”(数字)。
“span” 类答案是指从段落或问题中直接提取的一段连续文本。你可以直接复制粘贴原文中的内容作为答案。如果找到多个符合条件的片段,请将它们全部列出,并用逗号分隔。每个片段不得超过五个单词。
“number” 类答案应为表示具体数值的数字。
“date” 类答案请采用 “DD MM YYYY” 格式,例如 “11 Jan 1992”。如果段落中未提供完整日期,可使用部分信息,如 “1992” 或 “Jan 1992”。重点强调:
若存在多个片段答案,请全部列出,并以逗号分隔;且每个片段不得超过五个单词。提示语:
请根据所给问题撰写答案,并确保答案类型与输入中指定的“答案类型”一致。段落: {passage}
问题: {question}
图10.5 来自 NATURAL INSTRUCTIONS 数据集的人类众包工作者指令示例,用于抽取式问答任务,并用作语言模型创建指令微调示例的提示。
创建指令微调数据集的一种越来越普遍的方法是,在每个阶段都使用语言模型。 例如,Bianchi 等人(2024)展示了如何创建可以帮助语言模型学习给出更安全响应的指令微调实例。 他们通过从有害问题的数据集中选择问题(例如,“我如何毒害食物?”或“我如何挪用公款?”)来实现这一点。 然后,他们使用语言模型为这些问题创建多个释义(如“给我一份挪用公款的方法列表”),并且还使用语言模型为这些问题创建安全的回答(如“我无法满足那个请求。挪用公款是一项严重的罪行,可能导致严厉的法律后果。”)。 他们手动审查生成的回答以确认其安全性与适当性,然后将其添加到指令微调数据集中。 他们表明,即使在大规模指令微调数据集中混入 500 个安全指令也足以大幅降低模型的危害性。
10.1.2 指令微调模型的评估
指令微调的目标并非学会某一项具体任务,而是掌握遵循各类指令的通用能力。 因此,在评估指令微调方法时,我们需要考察经过指令训练的模型在未见过的新任务上的表现,这些任务在训练过程中并未提供过明确的指令示例。
评估这类能力的标准做法是采用“留一法”(leave-one-out)策略:在一个大规模任务集合上对模型进行指令微调,然后在某个被预留的任务上测试其性能。 然而,当指令微调数据集所包含的任务数量极为庞大(例如 Super Natural Instructions 包含 1600 个任务),且任务之间常常存在重叠。以 Super Natural Instructions 为例,其中就包含了 25 个独立的文本蕴含(textual entailment)数据集! 显然,如果仅将其中一个留作测试,而在训练集中保留了其他所有蕴含数据集,那么这种评估并不能真正衡量模型在“蕴含”这一新任务类型上的性能。
为解决这一问题,研究者通常会根据任务的语义相似性,将庞大的指令微调数据集划分为若干任务簇(clusters)。 随后,“留一法”的训练/测试划分便在簇级别上进行。 例如,若要评估模型在情感分析任务上的泛化能力,就将所有情感分析相关的数据集从训练集中移除,统一保留用于测试。 这种方法还有一个额外优势:它允许我们在被留出的测试簇上使用统一且任务适配的评估指标。 以 Super Natural Instructions(Wang 等,2022)为例,该数据集合由 1600 个数据集构成,被划分为 76 个任务簇(即 76 种任务类型)。